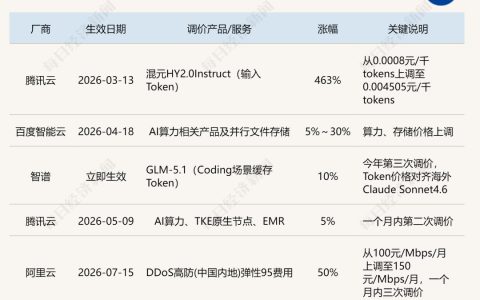
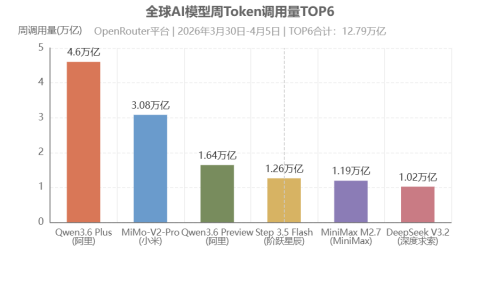
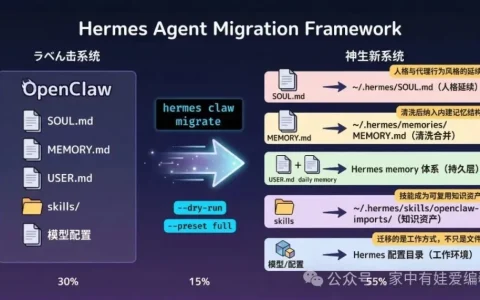
Claude Opus 4.7 正式上线,它到底比 Opus 4.6 强多少?值不值得立刻切?哪些场景应该升级,哪些场景继续用 4.6 更划算?——我们跑了 7 项真实测试,答案很明确。
同一个 prompt、同样的 max_tokens、同样的接口,分别调用 Opus 4.7 和 Opus 4.6,记录响应时间、输出长度和完成质量。
结果很明确:Opus 4.7 并不是所有任务都无脑碾压,但在 coding、debug、数学推理、创意写作这些高价值任务上,提升非常明显。
一、测试环境
- 网关:Crazyrouter
- 模型:claude-opus-4-7 vs claude-opus-4-6
- 日期:2026-04-16
- 方法:相同 prompt、相同 max_tokens、记录 wall time
二、7 项测试总表
| 测试项 | Opus 4.7 | Opus 4.6 | 结果 |
|---|---|---|---|
| 编程:线程安全 LRU Cache | 13.4s | 33.9s | 4.7 快 2.5x |
| 推理:多供应商成本优化 | 18.2s | 15.8s | 基本平手 |
| 上下文理解:needle in haystack | 3.1s | 3.0s | 平手 |
| 数学推理:工厂产能优化 | 10.0s | 20.5s | 4.7 快 2.1x |
| 创意写作:300 词短篇小说 | 16.3s | 101.1s | 4.7 快 6.2x |
| 代码调试:找 bug 并修复 | 11.1s | 58.6s | 4.7 快 5.3x |
| 多语言翻译:日/韩/德技术翻译 | 11.9s | 6.4s | 4.6 更快 |
一句话总结:高价值任务,4.7 明显更强;常规任务,4.6 依然很能打。
三、为什么说 4.7 最值的升级在 CODING?
让两个模型实现一个带 TTL 过期的线程安全 LRU Cache,同时涉及:数据结构、并发安全、类型注解、工程化组织能力。
- Opus 4.7:13.4 秒
- Opus 4.6:33.9 秒
不仅速度差了 2.5 倍,输出风格也差得很明显。Opus 4.7 给出的代码更现代:
- 使用
Generic[K, V]和TypeVar - 使用
__slots__优化内存 - 结构上更像可以直接拿去改造进生产代码的版本
Opus 4.6 也能写对,但整体更传统、更长、完成速度也更慢。如果你平时大量用模型写代码,4.7 的提升不是”营销文案里的更强”,而是真正有体感的提升。
四、DEBUG 提升甚至比 CODING 更夸张
给了一段故意埋了多个 bug 的 Python 异步代码,包含:
self.results跨调用污染asyncio.gather(..., return_exceptions=True)带来的结果类型问题- 同步包装层
run()的 event loop 使用方式不稳 - 返回结果逻辑有隐患
结果:
- Opus 4.7:11.1 秒
- Opus 4.6:58.6 秒
4.7 快了 5.3 倍。更关键的是,它不是只改一个点,而是先系统梳理所有 bug,再逐项解释,最后给修复方案——很像一个高级工程师在做 code review。
如果你的真实场景是读旧代码、排查 bug、修复异步逻辑、做 refactor,那 4.7 的价值会比你预想的大很多。
五、创意写作:差距最大的一项
让模型写一个 300 词左右的短篇小说,主题是”一个 AI 突然发现自己能通过传感器数据尝到食物”,要求有反转结尾。
- Opus 4.7:16.3 秒
- Opus 4.6:101.1 秒
这是所有测试里差距最大的:4.7 快了 6.2 倍。而且不是只有速度快,4.7 的文本完成度也更高——开头进入更快、感官描写更强、节奏更流畅、结尾更自然。
如果你用模型做内容生产、文案、播客脚本、视频脚本,4.7 的体验也会明显更好。
六、数学推理
3 台机器,不同产能、不同次品率、相同运行成本,目标是最便宜地生产 10000 个合格产品。
- Opus 4.7:10.0 秒
- Opus 4.6:20.5 秒
4.7 快了 2.1 倍。它不仅算对了,还会主动把每台机器的”单位合格品成本”先算出来,再推导最优策略。这类任务很像真实业务里的成本模型计算、资源配置方案推导、ROI 估算。
七、并不是所有任务都该切到 4.7
有意思的是,7 项测试里并不是所有项目都是 4.7 赢。
复杂推理:基本平手
在多供应商 API 成本优化测试里,4.7 用 18.2 秒,4.6 用 15.8 秒,两个模型都给出了正确结论。区别只是 4.7 输出更完整,4.6 更短、更直接,速度还略快一点。
上下文理解:平手
在长文本里做信息抽取,两者表现非常接近(3.1s vs 3.0s)。
翻译:4.6 反而更快
API gateway 技术说明翻成日语、韩语和德语,4.7 用了 11.9 秒,4.6 只用了 6.4 秒,而且质量也没明显差别。
八、真正合理的策略:按场景选模型
| 优先切到 4.7 | 继续保留 4.6 |
|---|---|
| 写代码、改 bug、代码重构 数学推导、结构化长输出 创意写作 |
翻译、信息提取 轻量推理 成本敏感的批量工作流 |
高价值任务上 4.7,常规任务上 4.6,才是最划算的用法。
九、用 CRAZYROUTER 切模型
切模型只需要改一个参数:
resp = client.chat.completions.create(
model="claude-opus-4-7" # 改成 claude-opus-4-6 即可对照
)
Crazyrouter 是 OpenAI 兼容 API 网关,切模型只改 model 参数,一个 KEY 调 Claude、GPT、Gemini 多个模型,不用换 SDK,不用改接入逻辑。更适合做真实路由策略:coding/debug 走 Opus 4.7,翻译走 Opus 4.6,常规客服问答走更低价模型。
十、结论
Opus 4.7 最大的价值,不是”所有任务都更强”,而是在 coding、debug、数学推理、创作这几类高价值任务上,提升非常明显。Opus 4.6 并没有被淘汰,翻译、上下文提取、轻量推理这些任务依然很有竞争力。
最聪明的做法:把最贵、最重要、最依赖质量的任务交给 4.7,把大量常规任务继续放在 4.6,按场景选择模型,这才是更接近真实生产环境的策略。
本文来自转载小飞哥估值课堂 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫