周末,codex一个大bug爆了。
在流式传输和自动化任务的时候,以5M/s的速度,持续往磁盘写日志。 每年大概要写640TB。要不了一年,就可以耗尽部分消费级SSD标的写入寿命。
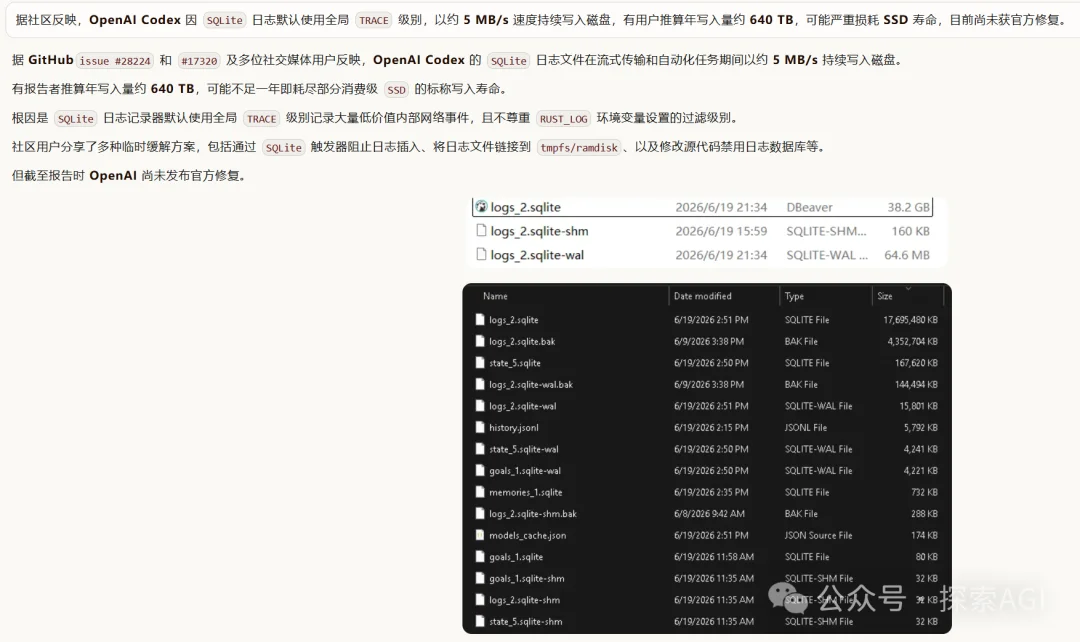
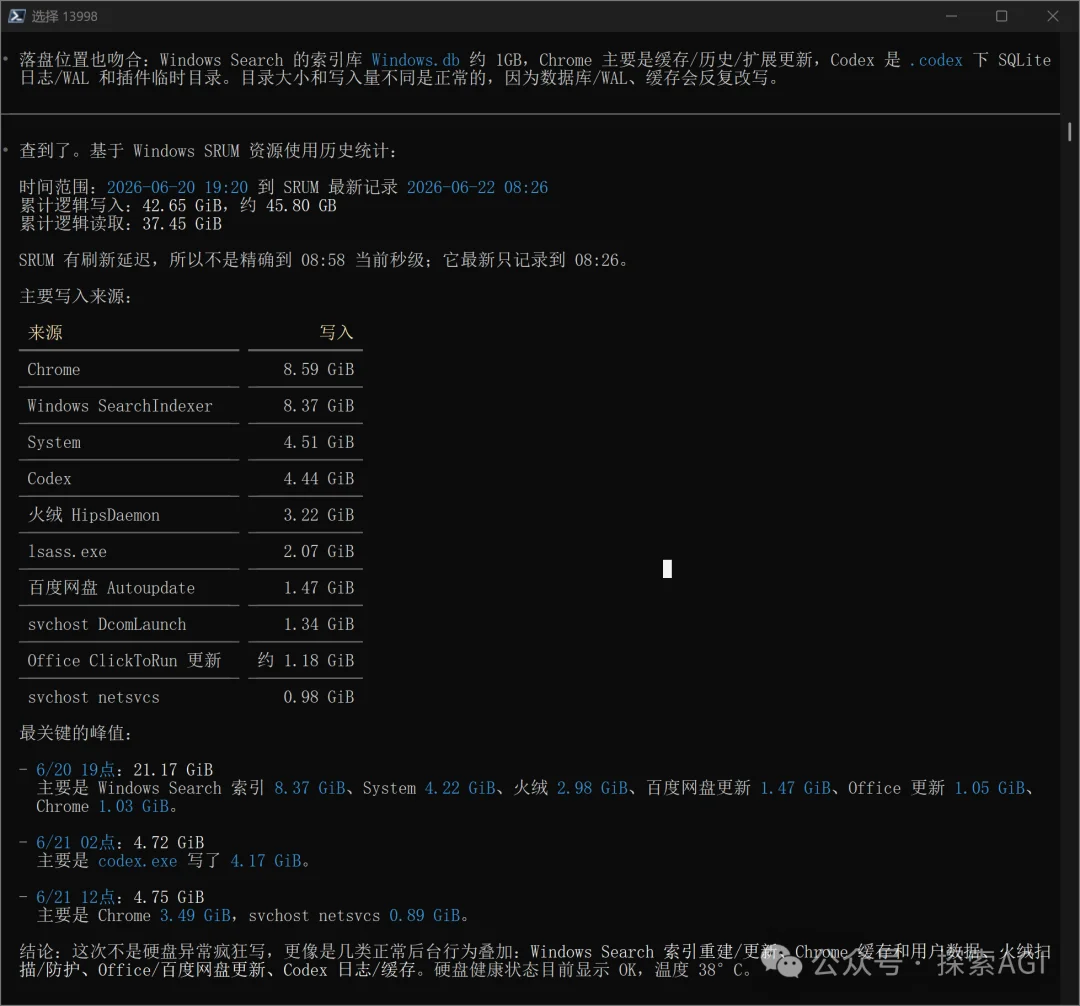
Github 上已经有不少issue在反馈这个事,数据也都列得明明白白。 机器开机跑了21天,主盘的总写入量(TBW,写进闪存的字节,不是你看到的文件大小)多了37TB,排查下来,主要的持续写入者就是codex的sqlite日志。
按这速度外推,一年640TB。而一块1TB的消费级 SSD,官方标称的写入寿命也就600TBW上下。一年就能把你这块盘的质保寿命整个耗干。
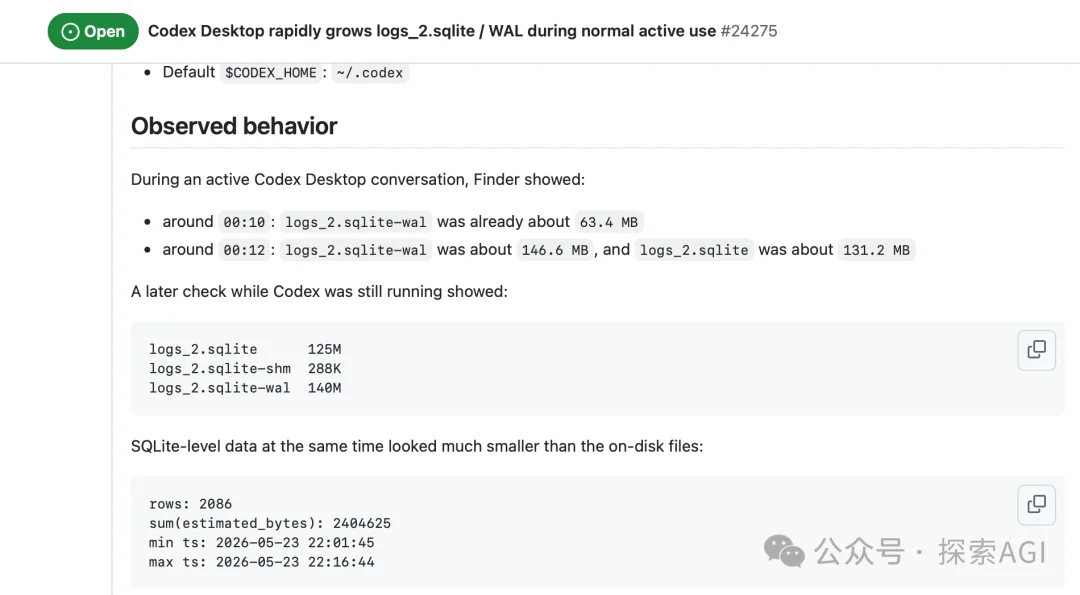
而且它不挑版本。CLI、桌面 App、VSCode插件全中招。
罪魁是~/.codex/logs_2.sqlite这个文件,里头70%以上是TRACE级别的日志。 什么inotify打开了ld.so.cache、websocket收了个包、tokio 内部状态,全给你怼进 sqlite。
更阴间的是它一边插一边删:15秒插进去三万六千行,文件大小看着没怎么涨,可底下的WAL一直在刷盘。可能盯着文件大小觉得才几百兆没事,其实写入量早就上天了。
评论区一片吐槽。 我说我电脑配置不低怎么越用越卡,原来在这儿等着我。 Codex 用久了卡顿、切会话要等好几秒、ccswitch 切换都跟着卡、 很可能都是这玩意儿在背后磨盘。。。。
有人算了下,256G的QLC固态可能只能称1个半月。。

还有网友表示,还不如隔壁Claude。那边的大文件都是虚拟机镜像,都是干活要用的东西;Codex这个日志纯粹是没啥用的内部噪音。
快速看自己的盘有没有在燃烧? Linux/Mac下直接看:
ls -lh ~/.codex/logs_2.sqlitesqlite3 ~/.codex/logs_2.sqlite “SELECT level, COUNT(*) FROM logs GROUP BY level ORDER BY COUNT(*) DESC”
要是TRACE占了一大半、文件还在不停长,那就是中招了。让codex自己查了下,端午没怎么用都写了这么多。
目前止血的办法有三个,从糙到稳。
最暴力的,直接拿sqlite触发器把日志写入掐死。反正这文件里只有诊断日志,没有你的对话历史,删了、屏蔽了都不心疼:
sqlite3 ~/.codex/logs_2.sqlite “CREATE TRIGGER IF NOT EXISTS block_log_inserts BEFORE INSERT ON logs BEGIN SELECT RAISE(IGNORE); END;”
温和一点的,把这个文件软链到内存盘(tmpfs),让它在内存里折腾,不碰你的SSD,重启自动清空:
mv ~/.codex/logs_2.sqlite ~/.codex/logs_2.sqlite.bakln -s /tmp/logs_2.sqlite ~/.codex/logs_2.sqlit
实在不想动命令行、家里又有第二块机械硬盘的,把这文件挪过去就行。 机械盘耐写,磨就磨吧。
不过这些都只是workaround,真正还是要openai抓紧修复。给sqlite sink老老实实接上RUST_LOG的过滤就完事了,issue里网友连补丁思路都写好了。可惜从4月挂到现在,官方一个回应都没有。
现在SSD什么价,大家心里有数,端午这几天没怎么用,都能给你写进去好几个G。 趁还没磨穿,自己先打个补丁吧。
世界果然是个巨大的草台班子!
本文来自转载探索AGI ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫