跑分跑了这么多年,新基准偏说FLOPS量不动智能体了,英伟达GB300一上来,就把上代甩开20倍。
同样一兆瓦电,英伟达最新的GB300 NVL72能同时扛住61400个智能体,上一代H200只扛得住大约2600个。
这中间,差了整整20倍。
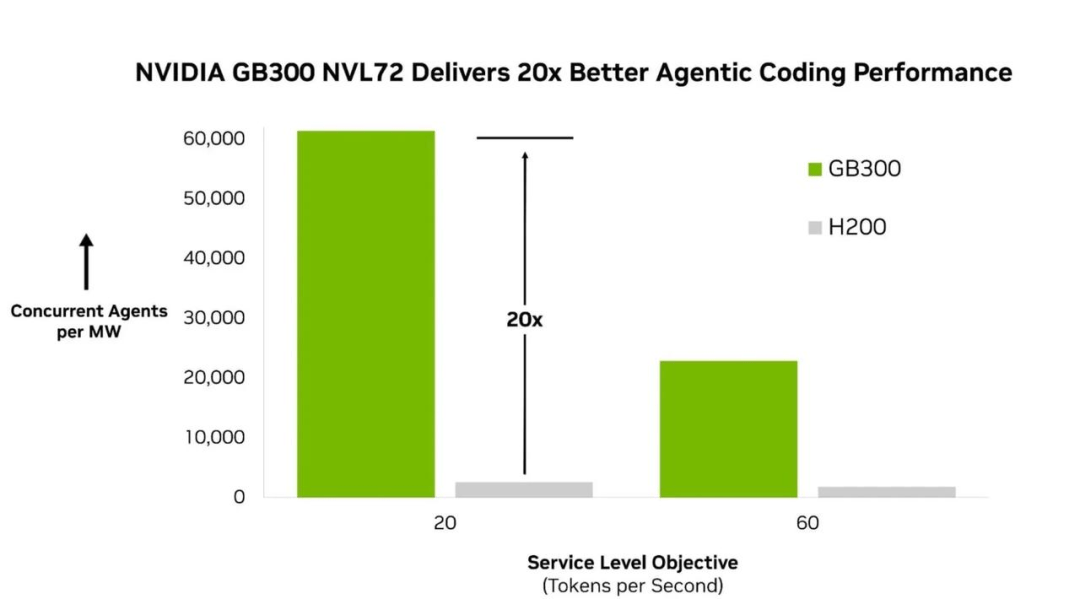
英伟达公布的AA-AgentPerf成绩:在每秒20与60个token两档服务标准下,GB300 NVL72每兆瓦的并发智能体数,都约为H200的20倍。
6月12日,英伟达刚放出这组数字的时候,外界第一反应是又一次性能炫技。
但真正变了的,并非这代芯片有多猛,而是丈量算力的那把尺子。
它就是独立评测机构Artificial Analysis发布的新基准:AA-AgentPerf。
Artificial Analysis在官方博客中将它称为业界第一个专门为「AI智能体(AI agent)」设计的推理基准。

它的主指标也和以往不同:并非每秒多少token,而是「每兆瓦并发智能体数(Agents per Megawatt)」。
通俗点说,就是每给系统供1兆瓦的电力,它能同时「养活」多少个智能体。
FLOPS量了这么多年,每秒吐多少token也用得好好的,为什么还要推出AA-AgentPerf这个新基准?
旧尺子
量不动智能体了
要回答这个问题,得先弄明白智能体跑起来时到底是个什么负载。
Artificial Analysis的判断很明确,2026年最主流的AI负载,和那些老基准当年设计时瞄准的东西,早就不是一回事了:老基准量的是定长的合成请求,还顺手关掉了生产环境里真会开的那些优化。
英伟达官方也打了一个贴切的比方:
一次普通的对话,是百米冲刺,模型接一个问题,吐一段回答,结束;但一个智能体干活,更像跑接力。
它把一个目标拆成几十上百个步骤,读文件、写代码、跑命令、看结果,再决定下一步,一棒接一棒,直到任务真正做完。
这一路下来,几十次甚至上百次的大模型调用串在一起,每一次都把越滚越长的上下文递给下一棒,还夹杂着编译、查库、跑搜索这些工具调用。
复杂度并非简单相加,而是层层相乘。

英伟达用「接力」比喻智能体负载。一个目标被拆成几十上百步,大模型调用与工具调用一棒接一棒,串成不断变长的长链。
问题恰恰就出在这里。
市面上现有的推理基准测试,量的都是单次调用,一个请求进去多久回来、一台机器能同时接多少个请求。
它们原本就不是为智能体设计的。链式调用、工具等待、上下文膨胀,这些东西对系统的压榨方式,和单次请求完全是两回事。
仅是长会话就藏着老基准的测试盲区:同一段长长的前缀,会一轮一轮重复出现,谁能把它缓存住、不必每次重算,谁就省下大笔算力。
再加上工具结果动不动把上下文撑爆、输出却常常只有几百个token,调度器和显存层级扛不扛得住这种忽长忽短的节奏,直接决定一套系统是顺畅运转还是当场崩掉。
这恰恰是固定长度的合成测试无法触及的地方。
对于真金白银买卡、建数据中心的人来说,他们真正关心的是这套系统到底能同时养活多少个干活的智能体,每一度电、每一块GPU又换来多少有用产出。
这些问题老基准测试答不上来。
第一个为智能体造的尺子
AA-AgentPerf的做法和老基准不一样,不喂那种长度固定的合成提示词,而是回放真实的编程智能体轨迹。
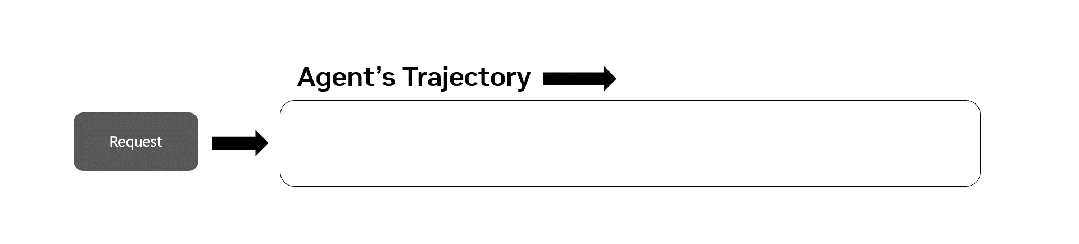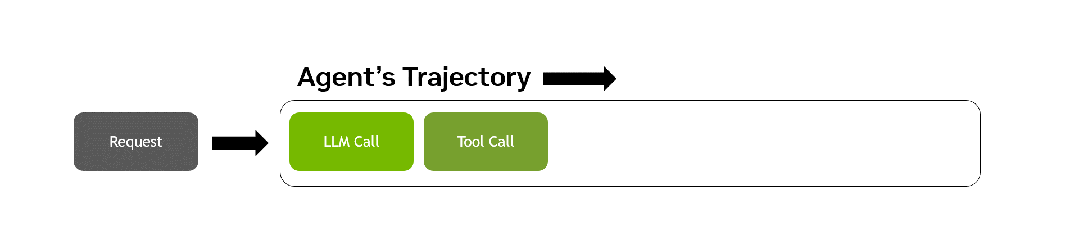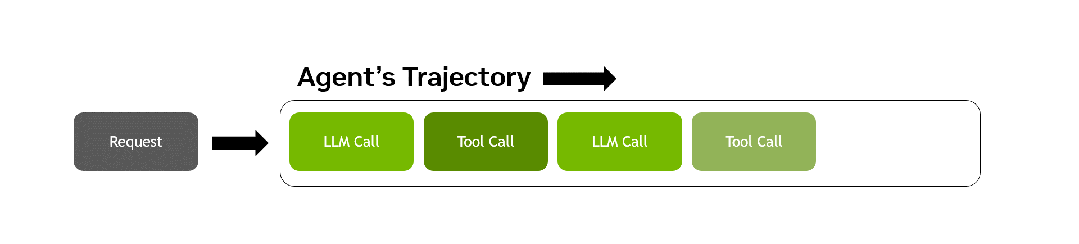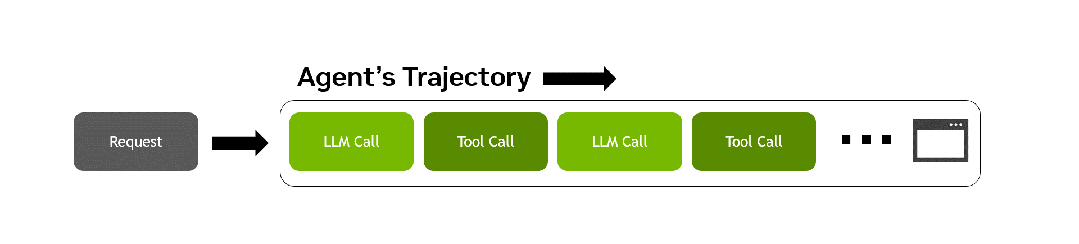
AA-AgentPerf回放的智能体轨迹示意。从一个请求出发,LLM调用与工具调用交替推进,直到任务真正完成。
这些轨迹,是让智能体去解真实代码仓库里的问题攒出来的,覆盖12种以上编程语言,一段会话最长能跑到200轮,上下文轻松冲破10万token。
输入长度从5千到13万token不等,平均约2.7万。真正把长度撑起来的,并非提示词本身,而是一轮轮累积的工具输出和对话历史。
更关键的,是它怎么算成绩。
它不去拼极致的并发数。并发一旦堆太高,每个智能体都慢得像爬,并发数再大,也只是中看不中用。
AA-AgentPerf反过来做:先锁死一个服务标准,每个智能体的输出速度、首字延迟(TTFT)都得达标,再看系统守住这条线,最多能扛住多少个智能体。
这套约束有个名字,叫服务等级目标(SLO)。
这套标准还分了几档,从每秒20个token的够用档,到每秒180个token的飞快档,每一档单独测一遍最大并发,对应市面上真实存在的几种服务水平。
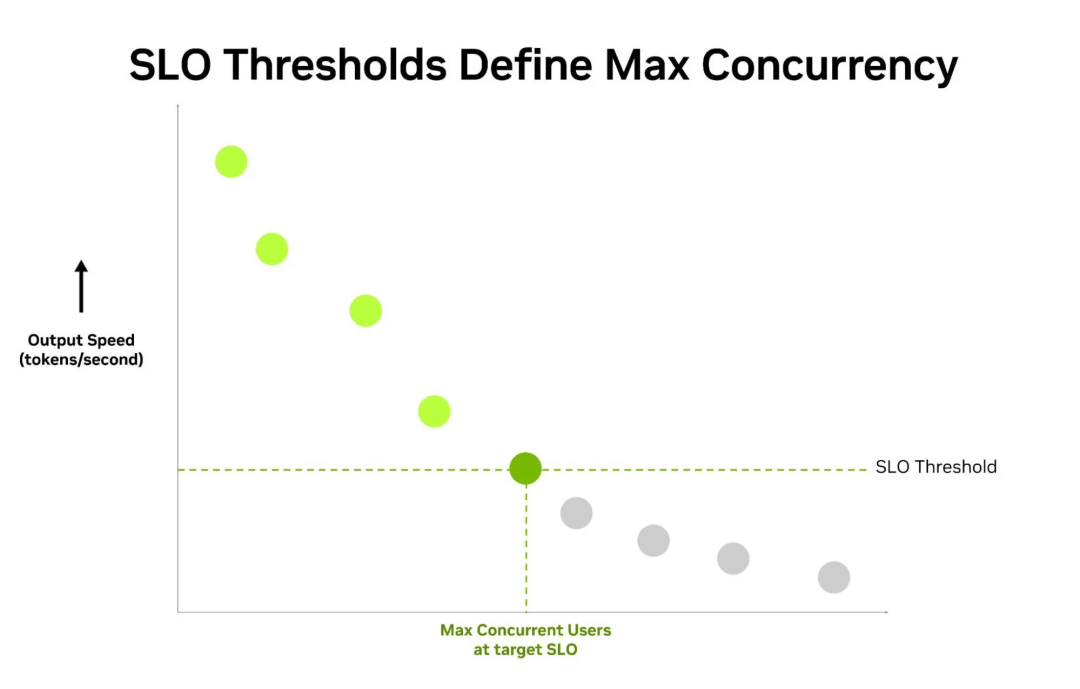
服务等级目标(SLO)如何卡住最大并发。绿点是达标区,一旦并发堆高、速度跌破门槛,对应的并发上限就是这套系统的成绩。
它还做了一件别的基准不太敢做的事,把厂商在生产里真会开的优化全都放开。
KV cache复用、推测解码、把预填充和解码拆开部署,这些以前常被基准一刀切关掉的招数,这次全部允许。
理由很简单:关掉这些优化测出来的,量了也没意义。
与此同时,它还盯着输出质量,不让某个优化靠牺牲回答质量去换并发数。这样一来,每多一项软硬件进步带来的提升,都能被它如实测量出来。
最后落到一个核心指标:每兆瓦并发智能体数。在一个电力越来越紧、能耗就是成本的世界里,这个指标,才是买家真正关心的那一个:从tokens每秒,到agents每兆瓦。
每兆瓦领先20倍
每块GPU领先40倍
在一个代表当下最强一类的前沿混合专家(MoE)模型测试里,GB300 NVL72每兆瓦能撑起61400个并发智能体,平均每块GPU扛起57.5个。
对照组H200,每兆瓦大约2600个,每块GPU只有1.4个。二者之间每兆瓦差出约20倍,每块GPU差出约40倍。
这两个数的含金量也不一样。
每兆瓦衡量的是同样一度电能买到多少智能体产能,是一笔能效账;而每GPU衡量的则是单块卡的服务密度,是一笔硬件账。
根据这两个数,就能直接换算自己手里那点电力预算,到底能跑起多大规模的智能体应用。
榜单上不止英伟达的GB300,还有AMD的MI355X。从单卡、整机到整机架,都摆出来同台竞技。
第一批结果里跑出了两条很明显的规律。
规律1:机架级系统天然更便宜,它能更充分地把推理拆开、摊到更多卡上,无论纯算力还是每兆瓦能效,都把单节点甩在身后;
规律2:从Hopper到Blackwell这一代的跨越,把系统能扛的并发数直接顶上了一个新台阶,并非小修小补。
从单卡到机架
系统级的胜利
从H200到GB300,这看起来像单卡性能的飞跃,事实上是一场系统级的胜利。
更为关键的是GB300 NVL72把72块GPU用NVLink连成了一个机架级的整体。
对这种庞大的混合专家模型来说,这才是要害:模型能整个摊开,专家分到一整片GPU上并行执行,而并非全挤在单卡里干耗。
CUDA核心在底下做了进一步优化,把跨专家之间的通信和计算重叠起来,让协调各路专家的那点开销被算力悄悄吞掉,而并非堆在时延上。
TensorRT-LLM则负责在并发会话不断往上涨的时候,把效率守住,比如把输入的处理和输出的生成拆成两件事,各自单独优化。
说白了,这个测试成绩,是硬件、互联和软件栈共同作用的结果。

GB300 NVL72机架。72块GPU经NVLink连成单一高带宽整体,这才是6万个智能体能协同运转的硬件底座。
把72块卡焊成一个高带宽的整体,每块GPU都能飞快地共享参数、KV cache和中间结果,这才是6万个智能体能协同跑起来的底气。
几条不能略过的边界
这里有几点需要注意,不能把基准测试等同于生产现实。
第一,6万这个数,并非一台机器同时跑6万个独立的大模型。
它是基准定义下的并发会话模拟,每个智能体走的是一条预先录好的轨迹,连工具调用都并非真去执行,而是用一段固定的CPU耗时去模拟。
这么设计,是为了让最终结果只反映算力本身的差异,但它和真实生产环境里能交付的服务能力,并不能直接画等号。
第二,基准成绩并非生产服务协议。
Artificial Analysis自己也说,这是一份还在快速变动的前沿快照,各家系统都还有没榨干的余量,成绩会随着软件优化一路向上爬升。
第三,AA-AgentPerf目前还是单一机构提出的标准。
它会不会像MLPerf那样,最终长成全行业公认的标尺,现在下结论还尚早。
参考资料:
https://artificialanalysis.ai/articles/aa-agentperf
NVIDIA Achieves Leading Agentic Coding Performance on First Agentic AI Benchmark
本文来自转载新智元 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫