谁才是最大赢家?
刚刚的,面壁智能联合 OpenBMB 搞了个端侧开源周。今天作为开源周的第一天,端出来的是个好东西 BitCPM-CANN,模型权重只需要约 200 MB 的内存,手表也够跑
同时,这是首款【基于国产算力平台训练】的【三值大模型】,并开源。对于这个模型,从量化算子到训练算法,全在华为昇腾上原生跑通
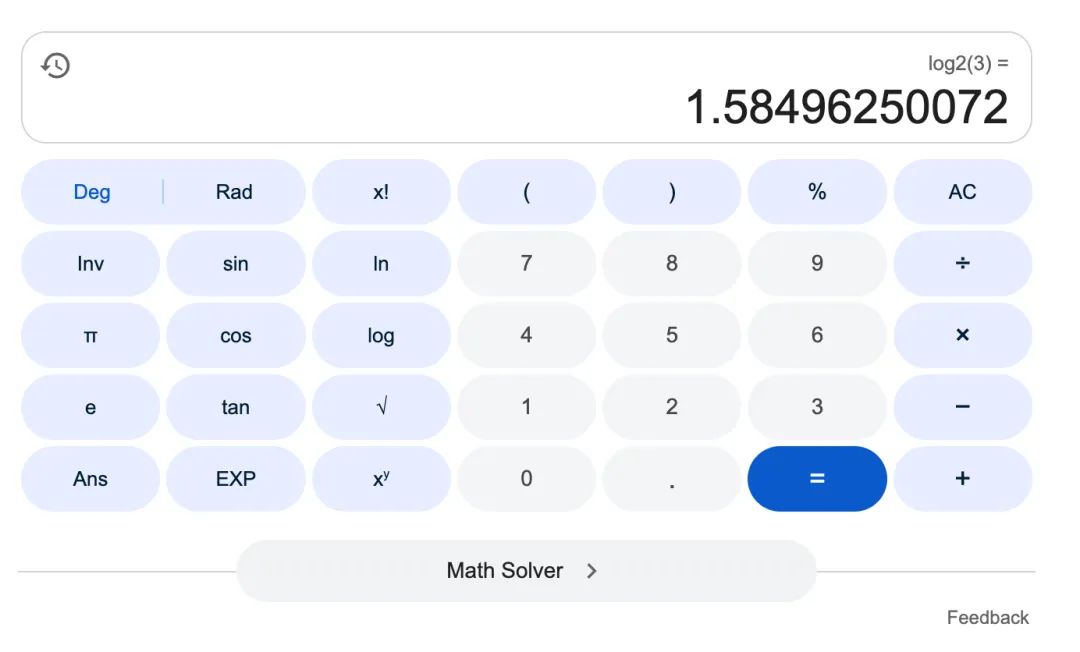
所谓三值大模型,其参数权重只保留:-1、0、1 三个状态,占用 1.58 位的比特…诶…没反应过来的同学,可以想一想高中数学,log2(3) 是多少嘞?1.58
比起常规下用 FP16 来存权重,减少了90%的尺寸(至于为啥是这么算的,后面我详细说,方便非 CS 专业的朋友听来当个饭后谈资)
除此之外,面壁的这个模型也一次端出了 0.5B 到 8B 四个尺寸,全系开源
只用 10% 的尺寸,保留了 95% 的能力
把尺寸压到 10%
在这里我得先说一下【模型参数】这个东西。大模型眼中的世界,是由一堆数字组成的,这些数字就是大模型的参数。我们说 DeepSeek R1 是 671B,指的就是它的参数大小是 671 B
参数是需要被存放的,常见的是 BF16(Brain Float16),每个参数通过浮点数的方式存成小数,比如 1145141919810 按 BF16 来储存的话,就是:0101001110000101,意为:在二进制下的 1.0000101₂ × 2⁴⁰
如果是按三值呢?1145141919810 -> +1,就是这么暴力。会把所有参数按算法切成三个选项:正的就是 +1 表示激活;负的就是 -1,表示抑制;中间的就是 0,表示断开

我之前写 MiniCPM-V 4.6 那篇的时候,做过一张量化精度对照表,从 FP16 一路排到 1-bit 的 BitNet
这里再插入一个信息,BitNet 刚出来的时候 只用 +1/-1 两种状态来存,所以是占了 1 个位宽的大小;之后 BitNet 1.58 发布,也是用的三值 +1/-1/0
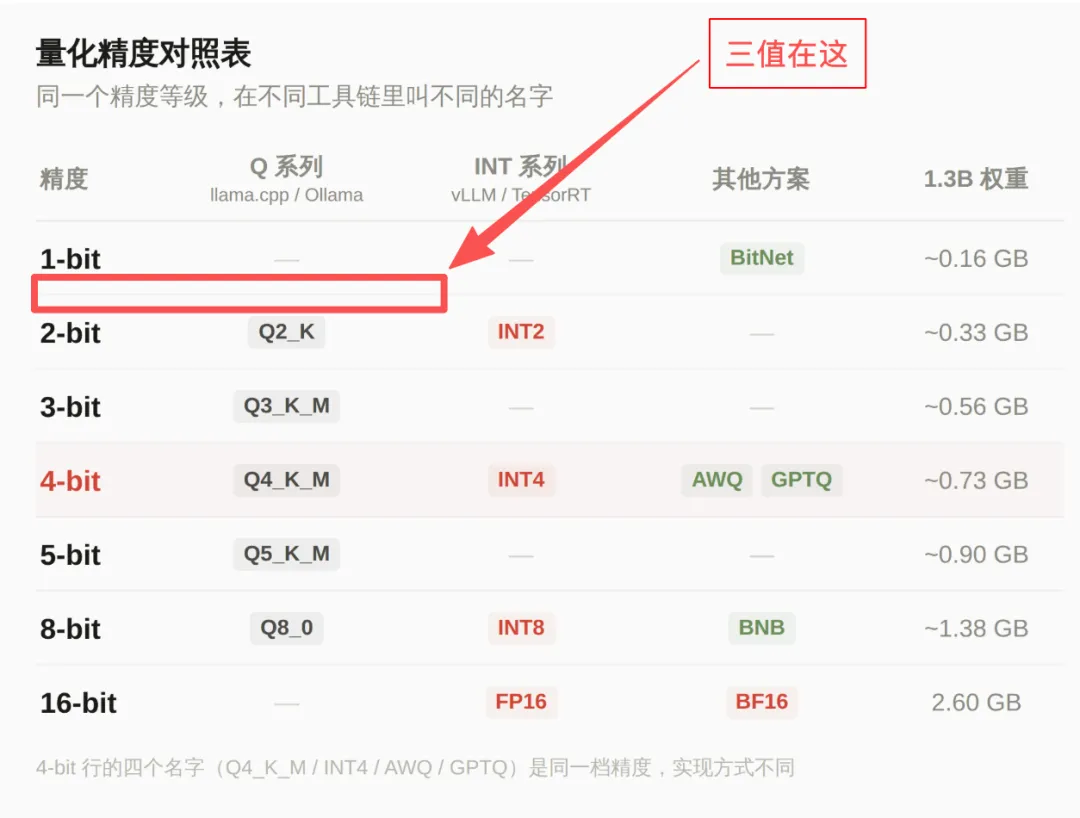
从直觉上想,如果把数据量化到这份上,大模型就可能变成一个智障;但经过专门的训练后,这模型和原版竟然相差无几
在模型的 model card 信息里有这么张图,我给拎了出来,大概就是跑了 11 项评测,把它的评分和自家全精度的 MiniCPM4 做了一对一对照,然后发现 1B 到 8B 三个档位,能力保留率都在 95% 以上。3B 档位保留率最高,97.2%。最容易因为精度丢失而崩溃的数学和代码任务,也稳在了全精度上限附近
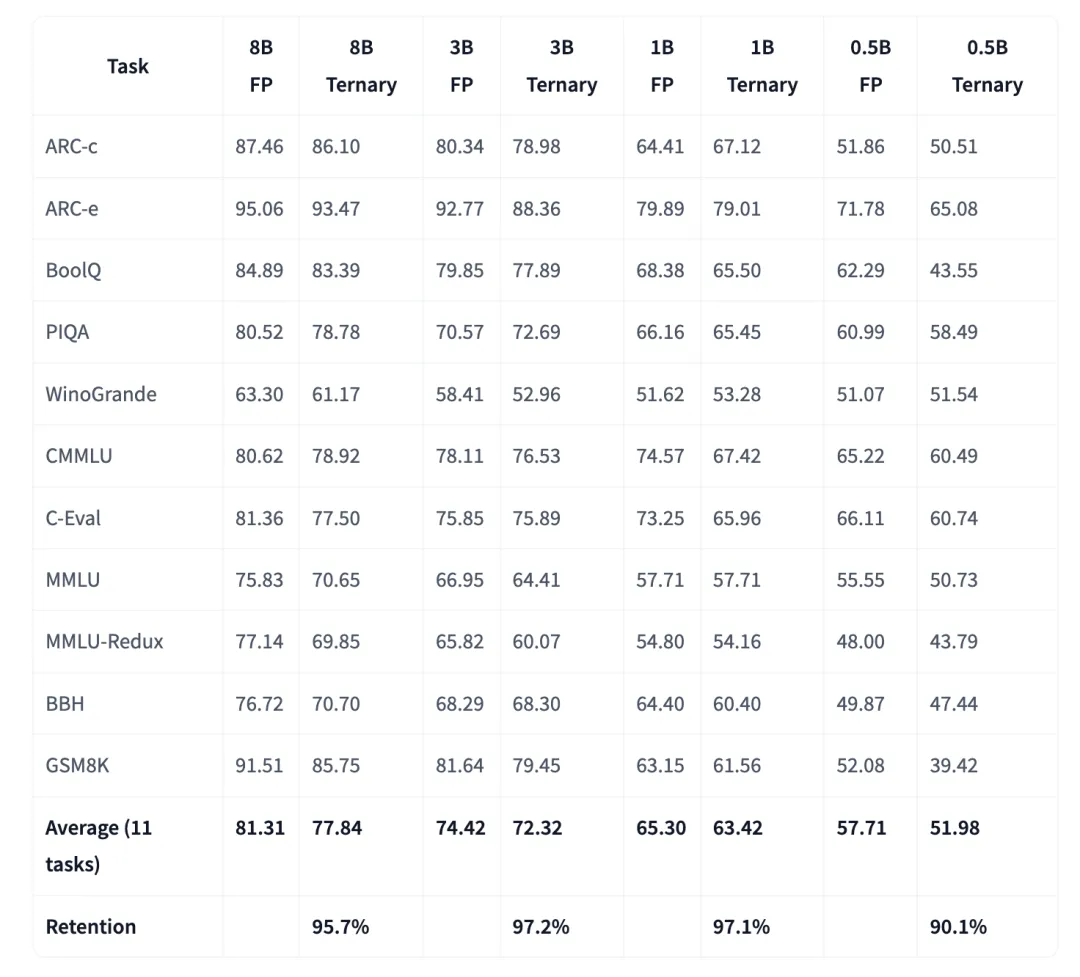
然后 0.5B 档位保留率会低一些,在 90.1%,这也说明了越小的模型对量化扰动越敏感,不过这方面的成因也找到了,是能继续优化的,面壁团队接下来会数据配比和课程学习上继续下功夫
国产算力的第一次
三值,在大模型在学术圈不算新物种,正如上文注释里提到的,微软研究院两年前发过 BitNet b1.58,验证了三值权重是训练可用的
那么,这次面壁的工作克服了哪些困难呢?大概是以下几点:
-
脱离 CUDA 生态:之前公开的三值工作,都是基于英伟达多算力卡的,很依赖于 CUDA 生态。在去昇腾上做的话,底层的量化算子得进行重写,训练流程、通信接口什么的也都要重新适配
-
规模推到 8B:BitNet 公开的模型最大在 3.9B,面壁这次的工作把整个尺寸拉到了 8B 的尺寸,那么训练稳定性、显存调度和多卡通信什么的,难度自然也都会提升
-
沉淀成了基础设施:这是一个值得称道的地方,面壁在 Megatron-LM 和华为 MindSpeed 上嵌了一个可插拔的量化并行线性层,量化训练和全精度训练共用了同一套检查点和通信框架,让 32K 的长序列训练也在这上面跑通了
至此,这套东西也算得上是在昇腾上做低比特训练的 best practice,后面再有人尝试做类似的东西,也有了现成的作业可以抄
往大了讲,这是国产底层算力生态在“极低比特大模型”这条前沿路线上的一次破局,说明证明了脱离 CUDA 体系,用纯血昇腾,一样能训模型
面壁的老本行
做量化大模型,行业里有两种路子
第一种,也是最常见的叫后量化(PTQ)。先用全精度把模型训完,然后再用算法把权重压成低位数。很多模型在发布的时候,会同时给到多个量化版本,正是这么来的。省事,成本低,但压到极低比特的时候,模型能力会断崖式下跌
另一种,是量化感知训练(QAT)。从训练的第一天起,就把模型放进三值的限制里去练。比如面壁的这个新模型,在整个学习过程中,必须学会在只有 -1、0、1 的条件下保持性能
在这个方向上,面壁其实做了很久了,面壁也是一直以“高效能”和“端侧部署”为技术品牌标签的。之前他们就用 QAT 的方法论摸出了稳定的学习率区间、数据配比和蒸馏策略。2025 年发布的 BitCPM4 系列的 0.5B 和 1B 两个模型发布时,在同尺寸 1.58-bit 公开模型里排第一
这次用华为的设备去做低比特训练,这些也都恰好用上了。比如 QAT 对学习率极其敏感,合理区间内可以激进,但越界就G,以前的炼丹手法可以迁移到昇腾上,省掉了大量试错时间
当模型训练完了之后,推理的收益就大了去了,差不多能让模型跑在原来 1/6 的现存上。现在高速内存的价格,已经涨得亲妈不认了,这玩意儿就越来越显得划算了
总结
面壁这次端出的 0.5B、1B、3B、8B 四个档位模型,跟全精度 MiniCPM4 相差无几,全部开源
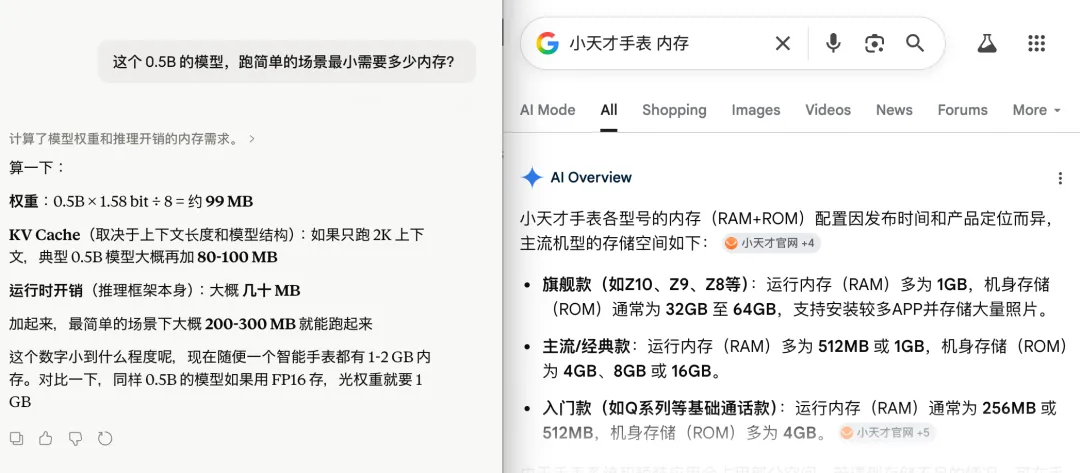
回收到最开始的内容,如果你直接去问 Claude:这个模型需要多大的内存?它会给你一个理论值:0.5B 乘以 1.58-bit,纯模型权重只要 99MB
但在实际工程里会稍微多一点,Embedding(词嵌入层)和 LM Head(语言模型头)要保留 BF16 的全精度才能好用,所以真实大小,需要约 200MB 内存…是说这个 0.5B 的模型,小天才还真能跑
开源地址:
https://huggingface.co/collections/openbmb/bitcpm-cann
https://modelscope.cn/collections/OpenBMB/BitCPM-CANN
本文来自转载赛博禅心 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫