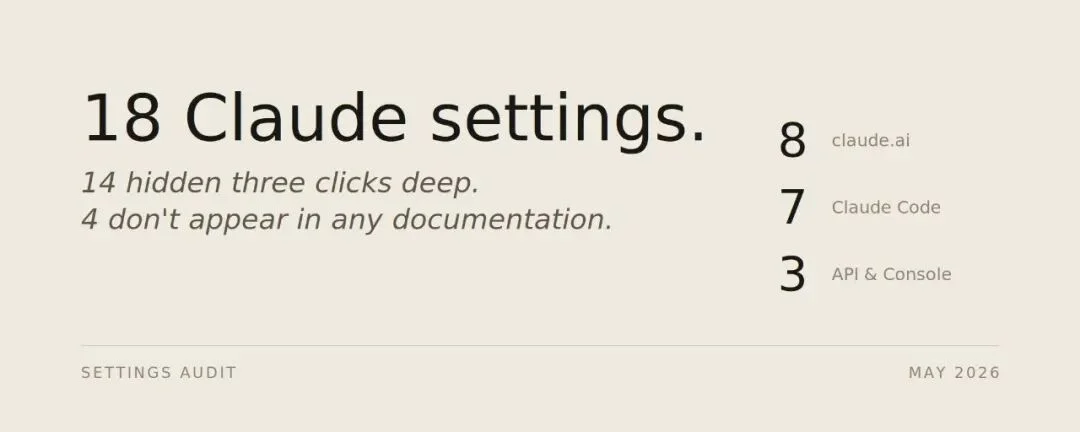
Mnimiy 在 X 上发布的 Claude 设置审计帖:18 个设置,14 个藏在三层菜单里,4 个文档里根本没有,分布在 claude.ai、Claude Code 和 API 三个平台
Claude Code 的 settings.json 里有 125 个配置键。官方文档只讲了大约 40 个。
剩下 85 个呢?只有泡 GitHub Issues、蹲 Discord 等工程师说漏嘴、或者凌晨一点对着 Claude Code 二进制文件 grep 的人才能摸到。这句话我读了两遍,觉得既荒谬又真实。
帖子 5 月 23 日发出来,24 小时内 3.6 万次浏览。18 个设置拆成三块:Claude.ai 占 8 个,Claude Code 占 7 个,API 和 Console 占 3 个。每个设置他都交代了三件事——在哪找、干什么用、怎么一行改掉。
我读完对了一下自己的配置,发现有 5 个地方是错的或者从来没碰过的。
「Most Claude users run with whatever Anthropic shipped six months ago. Their bill creeps. Their output drifts. They blame the model.」
Claude 回答不对劲的时候,第一反应永远是「模型变差了」。但有时候真相更蠢——你的设置还停在半年前的出厂状态。下面按平台拆开,挑最值得改的说。
01 记忆漂移
先说 Claude.ai 里最容易出问题的一个:Memory。
Memory 在 2026 年 3 月向 Free 和 Pro 用户全量推出。默认是把所有 Claude 觉得值得存的东西都存下来。听起来很方便。问题是,4-6 周之后,你的记忆库开始变质。
里面可能塞着什么?你某次随口说的「Python 里我习惯用 Tab」,一个三个月前已经关掉的项目上下文,一个你只玩了一次的角色设定。Claude 开始为一个「错误版本的你」优化输出。症状很微妙:回答里出现奇怪的假设,上下文莫名飘移,偶尔它会提到一些你完全不记得说过的事。
Mnimiy 给了两个修法。第一个:开启项目级别的 Memory 隔离,路径是 Settings → Capabilities → Memory → Scope per Project。打开之后,在某个 Project 里生成的记忆只待在那个 Project 里,不会溢出到其他对话。
「Turn on project-scoped memory. Memories from inside a Project stay in that Project. This alone fixes most drift.」
第二个修法我之前完全不知道:在任何对话里直接说 「forget what you remembered about [话题]」,Claude 会比对记忆库然后告诉你它删了什么,不需要去找任何菜单。这是一个对话内的快捷命令。
三层菜单才能摸到的功能,居然有个对话快捷键。太 Anthropic 了。
Exclusion list 也要配一下:在记忆设置里把你不想跨上下文出现的话题加进去——工资数字、家庭情况、客户名字、医疗信息。这些加进去之后,无论在哪里聊,Claude 都不会主动提及。
02 在错误的地方思考
Extended Thinking 默认开在 Opus 上。很多人不知道它有三档:Off / Light / Full。
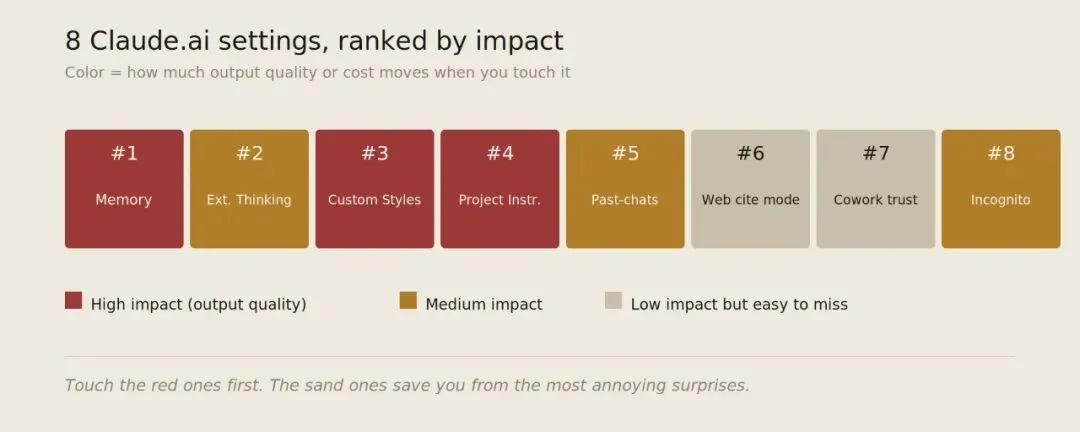
8 个 Claude.ai 设置的影响力排名:Memory 和 Project Instructions 影响最大,红色为高影响(输出质量),棕色为中等影响
Light 是「Claude 自己判断什么时候需要推理」,Full 是「每次都推理」。
问题在于:Extended Thinking 对摘要、翻译、格式调整、简单查询完全是浪费。这些任务打开之后,多出 3-12 秒延迟,多用 20-40% 的 token,答案一模一样。
Mnimiy 说他在第一周就把默认值切成 Light,Opus token 消耗降了 18-25%。需要深度推理时再手动开 Full。逻辑很简单。
但我不完全认同他把它说得这么容易。「你知道什么时候需要复杂推理」这个前提本身就有问题——很多时候你以为是简单任务,Claude 在 Light 模式下给出一个表面合理但有逻辑漏洞的答案,你接受了,两天后才发现不对。Extended Thinking 的价值有一部分恰恰在于你不知道自己需要它的时候。我用的方式反了很久,但切成 Light 之后,我也不确定我能每次都做对那个「该不该切 Full」的判断。
03 输出契约
Custom Styles 一开始的定位是语气调节(正式/简洁/解释型)。现在的 Custom Styles 其实是输出契约。
你可以粘贴一份 200-1500 字的指令文件,之后这个 Style 下的每次回复都会先执行这份契约。不是「语气更正式一点」,是「开头必须有一个具体数字或命名实体、句子不超过 18 个词、禁止用 em-dash、禁用 delve / leverage / robust 这几个词」。也可以写格式规则:「如果有三项以上内容,用 hyphen list,不用数字编号」、「代码块必须标注语言」、「如果问题本身有歧义,先回应主要理解,再问一个澄清问题」。
他自己有三个 Style 在轮流用:Draft for X、Code review、Summarize PDF。他说这三个替代了他 80% 的 saved prompts。
我想了一下,发现我现在很多重复指令其实应该做成 Style。每次都重新粘贴是因为懒得设,但最后反而更麻烦。这个设置在 chat input 的 style selector 里,不是在 Settings 里,找的时候容易找错地方。
还有一个不起眼的:Web search 引用格式。默认是 Inline,也就是引用标注直接插在正文里。你复制这段话粘贴到别的地方,那些标注就是指向虚空的乱码。切换成 Footnotes,来源排在最后,正文干净。这个设置在 Settings → Capabilities → Web search citations,不在 chat input 里。
04 空白的系统提示
Projects 那个 instructions 字段,他调查了「野生」的 Projects,70% 是空的。
这个字段的作用相当于:给这个工作区的每个对话注入一个系统提示。不填的话,每次对话都从冷启动开始。填了之后,你不用再每次重新建立上下文。
他说要像对待 CLAUDE.md 一样对待它:400 字以内,写清楚角色、默认怀疑程度、格式规则、什么不要做。然后每个月回来修剪一次。
400 字是个很准确的上限。再长就变成你自己都不会去读的文档了。
05 上下文预充电
这部分开始说 Claude Code,是我个人觉得信息密度最高的一段。
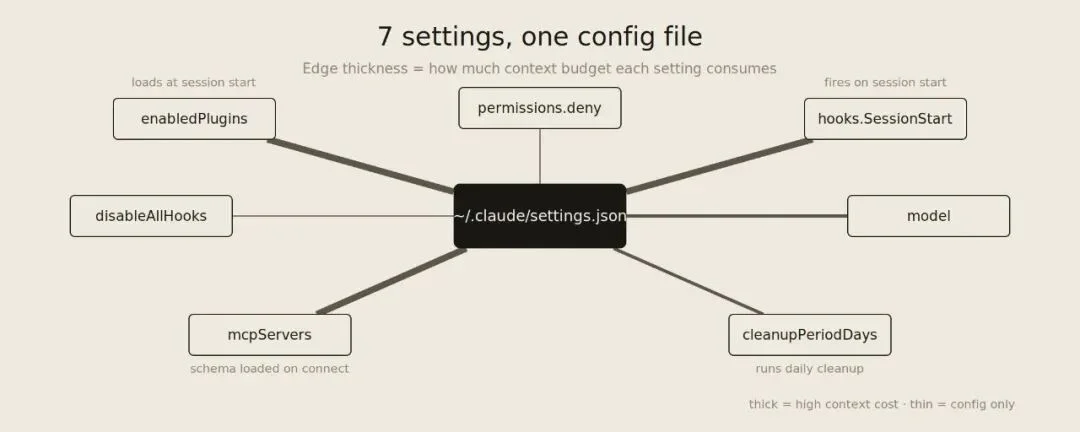
~/.claude/settings.json 的 7 个关键配置项:enabledPlugins、permissions.deny、hooks.SessionStart、disableAllHooks、model、mcpServers、cleanupPeriodDays,边线粗细代表对上下文预算的消耗程度
他审计自己的 ~/.claude/settings.json 时发现:自己装了 14 个插件,4 个是活跃的。
问题在于,每个被启用的插件都会在对话开始前把自己的 hooks、说明文件、工具 schema 加载进上下文预算。3 个你忘了的插件 = 对话还没开始就先燃掉 3-8K tokens。
修法:在 enabledPlugins 里把不用的插件设为 false。这样插件还在,只是不加载。需要的时候再 /plugin enable name@marketplace 单次开启。
MCP servers 同理。每个连接的 server 加载进上下文的 schema 是 800 到 6000 tokens。他有 12 个,常用 3 个,用 enabled: false 把其余的关掉,每次上线前按需打开。
这让我想到手机存储空间。每个人手机里都有几个「试了一次就忘了」的 App——某次旅行下的离线地图、朋友推荐的冥想软件、用了两天的习惯追踪器。它们不占你的注意力,但占你的存储。
Claude Code 的插件和 MCP servers 是同一种东西,只不过它们占的不是磁盘,是比磁盘贵得多的东西——上下文窗口。而且更阴险的是,磁盘满了手机会告诉你,上下文满了 Claude 只会悄悄变笨。你感知到的是「回答质量下降」,实际发生的是:你的对话从一开始就在一间比你以为的小 30% 的房间里进行。
我数了一下自己的:7 个插件,3 个 MCP servers。大概 3 个插件是上个月试完就忘的。清理它们的感觉,和删手机 App 一模一样——每个单独看都不值得专门删,但加在一起就是你一直在付的隐性税。
06 一个已知的 Bug
permissions.deny 理论上可以阻止 Claude 读 .env 文件、运行 rm -rf 之类的命令。
实际情况是:这里有一个已知 bug。规则写在配置里,debug 日志显示「0 matchers found」,Claude 照样读了文件。GitHub Issues #11544 有记录。
他的建议是双保险:permissions.deny 写上,但同时在 OS 层做 chmod 600 .env,让操作系统直接拒绝读取,不依赖 Claude 的规则执行。
我觉得这个 bug 值得单独拿出来说——不是因为它有多严重,而是因为很多人以为写了规则就安全了,实际上那道门没关上。
07 分支感知的上下文
hooks.SessionStart 是他个人最喜欢的一个。在 Claude Code 打开某个目录时自动执行命令。
他的用法:根据当前 git 分支加载不同的上下文文件。
主干分支加载 context-main.md,feat/auth 分支加载 context-feat-auth.md。每个文件只写当前分支相关的东西,体积小,上下文不溢出。
他说这一个改动把他的上下文预算浪费降低了 30%。
我之前的做法是一个大 CLAUDE.md 塞所有规则,结果项目越来越大,这个文件越来越长,实际上没什么人(包括 Claude)真的读完。分支粒度的上下文文件是个更聪明的解法。
disableAllHooks: true 也值得记一下:不是用来平时开的,是当 Claude Code 开始行为异常、你想排查是不是某个 hook 出了问题时,一键关掉所有 hooks 的紧急开关。知道它在哪里,等你需要的那天用。
08 按错位置放的缓存
API 部分,cache_control 是他说的成本影响最大的一个设置。
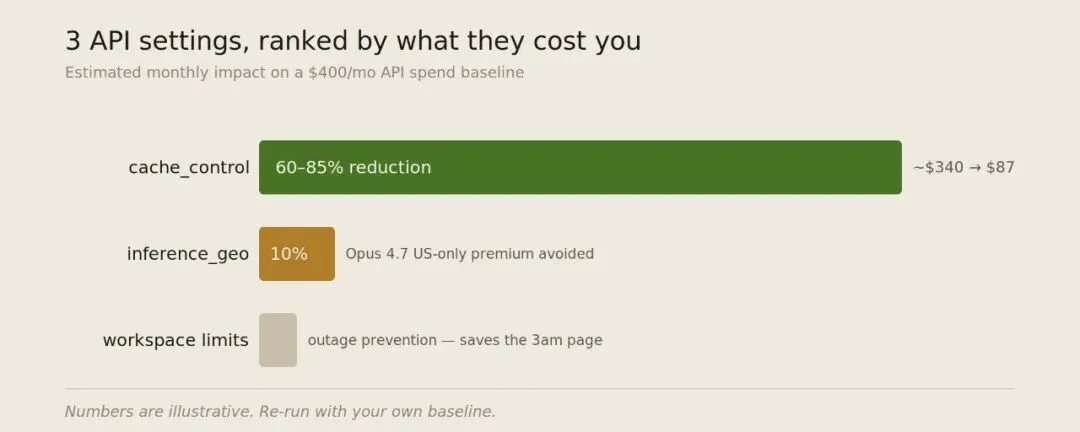
3 个 API 设置的成本影响对比:cache_control 正确设置可降低成本 60-85%($340→$87),inference_geo 避免 10% 美国专属溢价,workspace rate limits 防止凌晨意外停机
原理很简单:把 cache_control 断点放在静态内容和动态内容的边界上,之后每次请求,断点之前的内容只收取 10% 的价格。
问题在于,大多数人把断点放在了用户消息后面——也就是动态内容那里。每次 system prompt 都在全价重新计算。
「Fixing the breakpoint cut a $340/month bill to $87.」
正确做法是把断点放在 system prompt 结束的地方,用户消息之前。TTL 设成 1 小时("ttl": "1h")给每天不变的 system prompt。
缓存写入比正常贵 25%,缓存读取只要正常的 10%。只要同一个 prefix 在 TTL 内被读两次以上,就已经回本了。
还有一个:inference_geo。用来锁定推理的地理区域。美国专属数据驻留在 Opus 4.7 以上会有 10% 溢价,但这个不在标准定价页上,你是在账单里才看到的。他建议先确认一下,合规要求是真的必须还是只是「法务说要小心」。如果是后者,去掉这个参数,每次 Opus 调用立省 10%。
09 20 分钟的审计
他最后做了一个 18 项清单,说「走一遍,20 分钟,大多数人能修掉 6-8 个,有些人能修掉 14 个以上」。
我觉得他低估了一件事:很多配置的问题不是「你不知道怎么配」,而是「你不知道你没配」。Memory 漂移,你感觉到的只是「Claude 最近怪怪的」。Extended Thinking 全开,你感觉到的只是「有时候挺慢的」。MCP servers 一直加载,你感觉到的只是「好像上下文不够用」。
这些症状都很难直接对应到一个设置。更常见的反应是——把锅甩给模型。
他另外列了 4 个候选设置,最后没放进文章:Adaptive Reasoning toggle(测了一个月没发现有差异)、Skill auto-activation(调得很好,不用管)、Dispatch mobile-to-desktop(有用但不是设置问题)、per-workspace max_tokens ceiling(省钱但会破坏代码生成,不适合推荐默认值)。
我对前两个也有同感。Adaptive Reasoning 是那种「你以为调它很重要」但实际上模型自己判断得挺准的设置,手动干预反而适得其反。
10 对我们意味着什么
Anthropic 出货了 125 个配置键,文档覆盖 40 个,剩下的 85 个分散在 GitHub Issues 和工程师的 Discord 消息里。
这件事本身说明了一个问题:产品的默认值是写给普通用户的,不是写给认真用的用户的。默认打开 Extended Thinking、默认全局记忆、默认全量加载所有插件——这些设置对新用户很友好,但对每天用 8 小时的人来说是在燃钱和上下文。
我读完这帖子做的第一件事,是去数了一下自己有几个 MCP servers 是开着的。答案是 5 个,其中 2 个上次用是三个月前。清理完之后,每次开 Claude Code 少了大概 4-5K tokens 的预加载。不是什么大数字,但如果每天开十几次,一个月下来上下文的空间感很不一样。
他另外提到了一个叫 cleanupPeriodDays 的设置,默认是 30 天。这个数字控制 Claude Code 保留多少天的 session transcript 和调试日志。
如果你有在用 Dreaming(Claude Code 的后台学习功能),30 天只能学一个月的操作。改成 180 天,Dreaming 的信号量是 6 倍。磁盘代价大概是 200MB。
这个设置在 Anthropic 的任何公开文档里都没有。这也是他帖子标题里「4 aren’t in any docs」的那 4 个之一。
他写这帖子的时候说:「walk the checklist tonight. Most of you will fix 6-8 things.」
我觉得他有一个地方没说清楚:他把这 18 个设置当作一份「审计清单」来写,暗含的假设是——用户知道自己有问题,只是不知道问题在哪。但实际情况更复杂。大多数人不是「不知道怎么配」,而是根本没意识到自己在跑一个劣化的配置。心理模型是「我装好了,它就该一直是对的」。
Claude 不会告诉你「你的 MCP servers 正在白白吃掉 6000 tokens」,它只会默默在剩下的空间里挤出一个不太好的回答。你能感知到的只是:Claude 变笨了。
我还没想清楚这到底是 Anthropic 的产品哲学问题,还是纯粹的文档债务——85 个未文档化的配置键,这是故意的吗?是「先发功能再写文档」的创业公司节奏,还是某种刻意的筛选机制,让愿意 grep 二进制文件的人获得隐性奖励?我不确定。但有一件事我觉得可以确定:如果你现在觉得 Claude 变笨了,在发那条抱怨的推文之前,先花 20 分钟走一遍你的设置。
你大概率会发现,你一直在跟一个戴着六个月前面具的模型说话。
数据来源:Mnimiy (@Mnilax),X,2026-05-23;x.com/Mnilax/status/2058269663788736907
本文来自转载深思SenseAI ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫