百度开源Unlimited OCR!3B参数500M激活,一口气读完40页不失忆。作者疑似DeepSeek出走的OCR核心大神。
就在刚刚,百度闷声干了票大的!
最新开源的Unlimited OCR,总参数3B,实际激活仅500M——放在大模型时代几乎是个零头。
但就是这个小到离谱的模型,在OmniDocBench v1.5上拿下93.23%的综合分,v1.6更是达到93.92%,直接刷新了端到端SOTA。
什么概念?v1.5同台竞技的选手里,235B的Qwen3-VL拿了89.15,72B的Qwen2.5-VL拿了87.02,不公布参数量的Gemini-2.5 Pro也只有88.03。激活参数不到它们零头的选手,反手把它们全甩了。
更离谱的是,它还干了件之前没有OCR模型干成过的事:一口气解析40多页文档,不失忆、不降速,一次推理从第一页读到最后一页。
目前,模型和代码都已同步上线GitHub和HuggingFace。
GitHub:
https://github.com/baidu/Unlimited-OCR
Hugging Face:
https://huggingface.co/baidu/Unlimited-OCR
为什么所有模型都在「逐页失忆」
说到OCR,现在模型笨得让人意外。
它们会把一件原本连贯的长程任务,硬生生切成几十个互不相干的小任务,再靠一个外部调度器把结果勉强缝起来。就像在跑一个for循环,处理完一页就把记忆清空,再从头开始下一页。
能用,但本质上只是工程的权宜之计,离真正的智能还差着一大截。
究其原因在于,随着输出越来越长,标准注意力机制下的KV缓存像滚雪球一样疯涨——内存吃不消,速度越来越慢。
这才是逼着所有模型逐页处理、频频「失忆」的真正元凶。
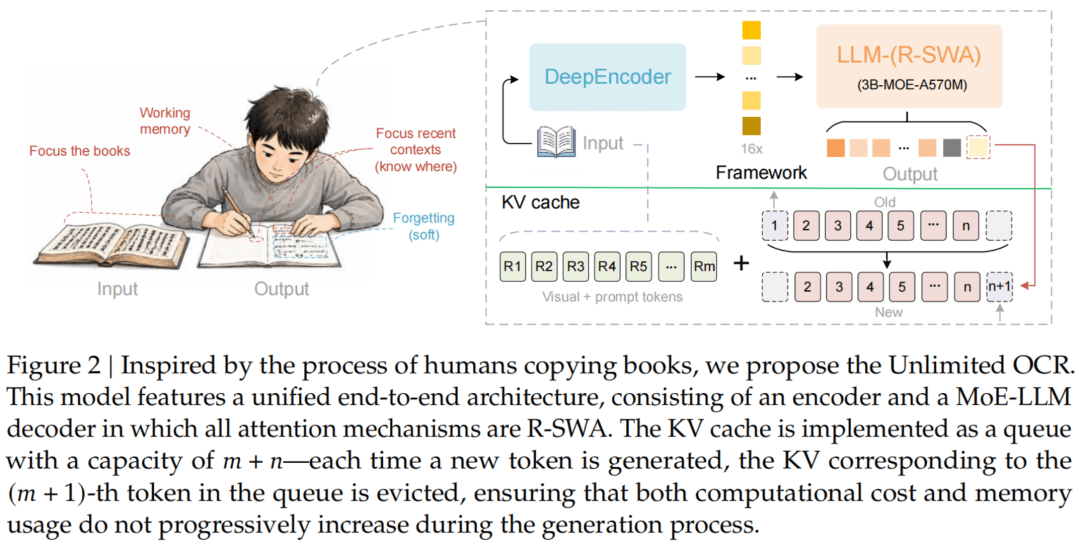
但人类抄书,从来不是这么干的。
我们会维持一种连续的认知状态——眼睛盯着三个点:原书、刚写下的一小段、即将要写的下一个字。
早些写过的内容慢慢淡出脑海,最近的上下文用来盯住当前进度。
这种能力有个很妙的名字:「软遗忘」(soft forgetting)。
正是靠着这种「该忘就忘」的本事,人才能在极低认知负荷下扛住超长任务。比如,抄一本书、译几百页、连续转录数小时音频。
百度想做的,就是把人类这种「原文全局可见、记忆只保留最近几行」的注意力方式,搬进模型里。让OCR告别失忆。
R-SWA:把「抄书的秘密」写进注意力
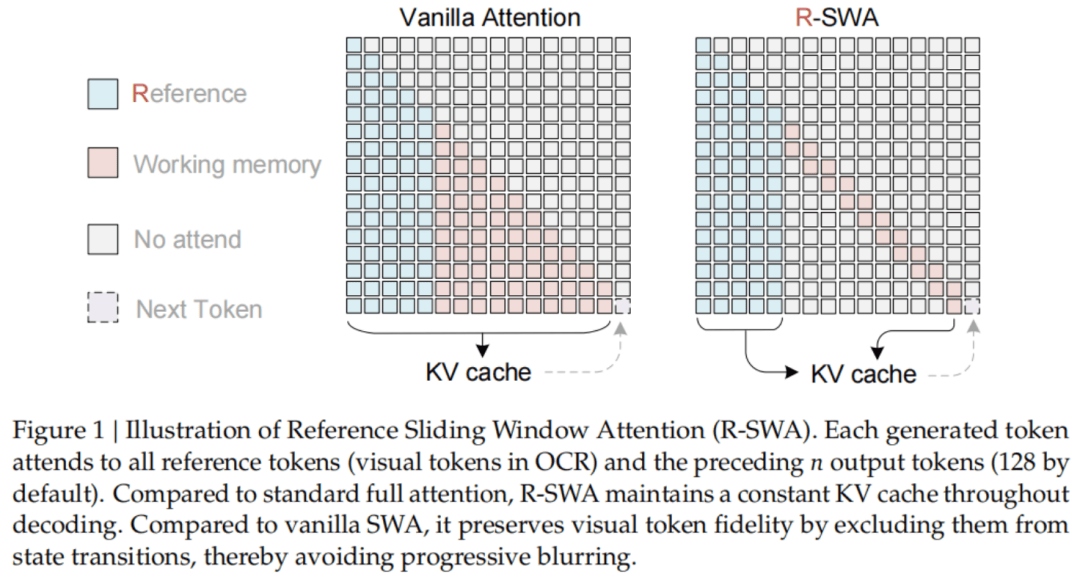
顺着这个思路,百度提出了报告里的核心技术——参考滑动窗口注意力(Reference Sliding Window Attention,R-SWA),精确对应前面说的人抄书时的注意力模式。
具体来说,每生成一个token,R-SWA都会去看全部「参考token」,也就是整张图像的视觉token和提示词,保证模型始终「看得见」完整原文。
但在输出这一侧,它只回看前面128个token,就像你抄书时只瞄一眼刚写的那几行。
落到实现上,Unlimited OCR把所有注意力层全换成R-SWA,从而把KV缓存变成一个固定容量的队列。
每生成一个新token,最老的那个就被挤出去,大小始终不变。输出1万个token和10万个token,内存占用是完全一样的。
报告中Flash Attention v3的延迟测试也一目了然。
DeepSeek OCR的标准MHA随着解码步数增加,每步耗时稳步攀升;而Unlimited OCR的R-SWA从头到尾一条平线,纹丝不动。

一次推理,读完几十页
这里还有一个至关重要的配合:DeepEncoder。
这个最初在DeepSeek OCR中登场的编码器,能把一张1024×1024的PDF页面压缩到仅仅256个视觉token,压缩率高达16倍。
而且由于视觉token在R-SWA下不参与状态转移,因此无论文档多长,图像信息永远清清楚楚,不会随解码过程逐渐退化。
配合DeepEncoder的极致压缩和R-SWA的恒定缓存,Unlimited OCR在标准的32K上下文里,一次前向推理就能转录数十页文档。
结果显示,同时输入20页文档,转录与原文逐字比对的编辑距离仅0.057;即便输入40页以上,依然控制在0.11以下,衡量重复输出的Distinct-35高达97%——几十页一口气转录,几乎没有复读。
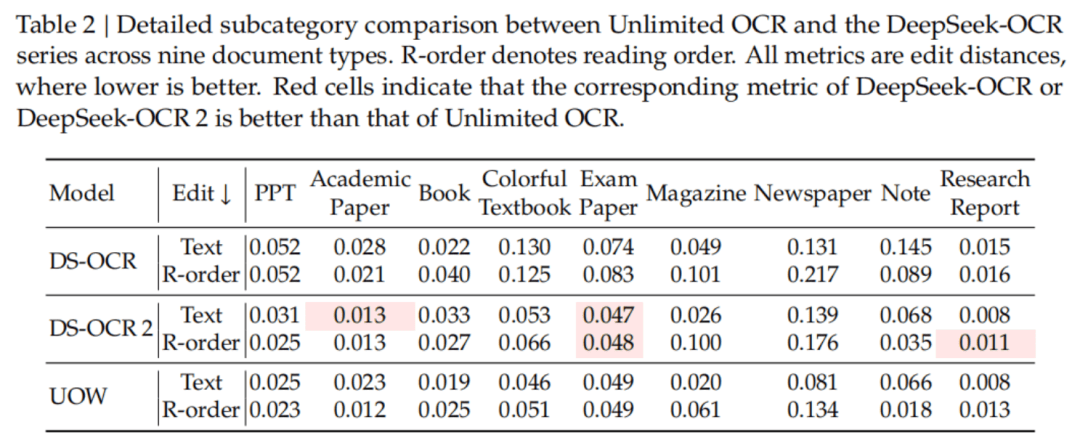
在OmniDocBench v1.5上,Unlimited OCR拿到93.23%的综合得分,比DeepSeek OCR的87.01%高出6.22个百分点。
文本编辑距离从0.073降到0.038,公式CDM从83.37飙到92.61,表格TEDS从84.97升至90.93。
在更新的v1.6上,同样以93.92%拿下端到端SOTA。
效率方面同样碾压。
输出达到6144个token时,Unlimited OCR的TPS是7847,DeepSeek OCR已经掉到5822,差距高达35%。
别忘了,这是一个500M激活的MoE小模型,在DeepSeek OCR基础上仅继续训练4000步的结果。
投入不算大,但效果拔群——R-SWA对解析任务是一种真正的「免费午餐」。
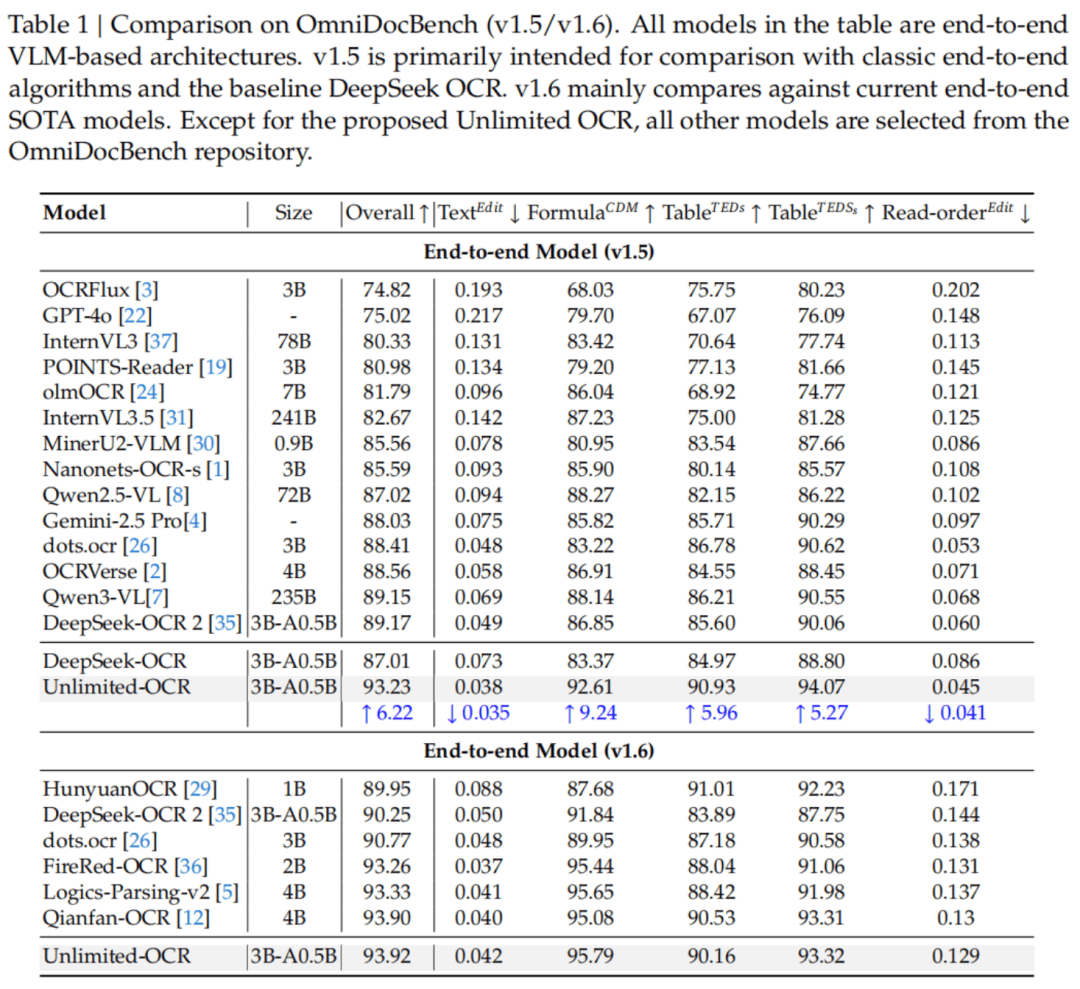
九大文档类型的细分对比中,PPT、论文、杂志、报纸无一短板,Unlimited OCR在文本和阅读顺序两项上全面超越DeepSeek OCR,且在七个类别中领先DeepSeek OCR 2。
一位神秘的技术总监
跑分说完了。但这份报告真正有意思的地方,是行文方式。
从副标题的语气到技术的叙事,读过DeepSeek那几份技术报告的人,几页下来就会觉得似曾相识。
末尾还断言R-SWA是通用解析机制,而OCR只是第一站。
一篇OCR报告,硬是写出了探索通用智能的味道。
然后,是那个最让人在意的地方——作者名单。
核心贡献者三位:Youyang Yin,Huanhuan Liu*(项目leader),YY†(技术总监)。
两个人用真名,唯独技术总监挂了个两字母缩写。有点意思。
虽然论文没多说,但GitHub致谢栏却把线索递了过来:Deepseek-OCR和Deepseek-OCR-2,排在致谢前两位。
顺着这条线往回找。DeepSeek OCR从一代到二代,核心作者始终三个人:魏浩然、孙耀峰、李宇琨。同一支小队伍,从无到有。
今年4月DeepSeek发V4,魏浩然名字后面多了星号——已离职。
三个人里,只有他已经公开离开。
再看履历。魏浩然,阶跃星辰出身,主导开发了端到端OCR最早跑通的开源标杆GOT-OCR2.0。到DeepSeek后,更是一手搭起整条OCR线,DeepEncoder、MoE解码器,一代到二代都是他的团队。
能力、时间线、署名方式,三条都对得上。
国内OCR圈不大,能做出R-SWA这种级别突破、还对DeepSeek OCR架构有「亲手做过」级别熟悉的人,一只手数得过来。魏浩然是其中最显眼的那一个。
如此一来,YY大概率就是魏浩然了。
百度,依然能打
过去几年,PaddleOCR几乎是国产OCR的代名词。开源、轻量,产业落地最广——从手机端到服务器到嵌入式设备,覆盖了最主流的应用场景。
不过之前百度更侧重产业应用。稳定性、部署成本、场景覆盖是强项,「用前沿研究理念重塑OCR范式」这个方向并非其叙事重点。
而魏浩然做的,恰好就是这件事。
从GOT-OCR2.0的端到端一次解析,到DeepSeek-OCR的视觉压缩,再到R-SWA——先想清楚OCR应该长什么样,再做出来。
一边是产业落地最成熟、场景覆盖最广的工程底座;一边是端到端长程解析最前沿的研究品味。两者叠加,补齐的不只是一个技术短板,而是一种「既能大规模铺开、又能持续引领范式」的完整能力。
百度今年把AIDU人才计划升级为集团级项目、薪酬不设上限。对一个想把研究做到落地的人来说,百度多年铺下来的产业底座,比单纯的高薪更有说服力。
魏浩然如果真的选了百度,逻辑就很清楚——这里有最成熟的产业底座,也有把研究推到前沿的空间和资源。
如果他真的把R-SWA推广到ASR和翻译,那百度手里握着的就不只是一个OCR模型,而是一套通用长程解析的技术框架。
论文展望里还留了一句:下一步,上下文窗口训到128K,构建prefill pool让模型学会自动翻页。
如果做到了,OCR就不再是识别一页文字,而是理解一整本书。
参考资料:
https://github.com/baidu/Unlimited-OCR
https://huggingface.co/baidu/Unlimited-OCR
本文来自转载新智元 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫