评测
-
Markdown还是HTML?这是个蠢问题!
昨天,Claude Code团队的Thariq发了篇爆文,标题叫:HTML是新的markdown。他说他几乎不再写markdown文件了,转而让Claude Code给他生成HTM…
-
AI接管浏览器!实测Codex Chrome:简单任务翻车,复杂任务反而成了
OpenAI这次不追求取代浏览器了。 OpenAI 又一次悄悄地给 Codex「补课」了。 北美世界 5 月 7 日,OpenAI 官宣 Codex for Chrome 扩展功能…
-
字节/腾讯/阿里 Agent 开发岗面试题横评:三家在考什么,我面完才明白
上个月密集面了字节、腾讯、阿里三家 Agent 开发岗。 一个很真实的感受:同样一个问题,三家的追问方向完全不一样。字节盯着训练流程追问三层,腾讯拉着你聊协议设计聊了半小时,阿里则…

-
大模型不认识马嘉祺?我们做了一次全链路排查
MiniMax M2 系列受到了开发者社区的广泛关注,不少用户在深度使用中发现了一些个例问题,其中“模型无法说出马嘉祺”这个问题引发了较多讨论。 我们也注意到,社区中有不少开发者对…
-
行业首创空间3D显示,还能主动提醒和帮忙叫车,千问AI眼镜这操作真把我看愣了
牛马打工人心酸三件套,看看友友们躺枪没: 出门忘看天气预报淋成落汤鸡;赶时间叫车在APP里戳半天才点上确认;工作久坐8小时颈椎已经在喊救命了…… 说出来大家可能不信,这些需要我们时…
-
字节 Doubao-Seed-2.0-lite 260428 测评
短的结论:能说会道的小天才 基本情况: 字节 Seed 团队在春节发布的 Seed 2.0 Pro 可谓是当时智力巅峰,但发完之后便进入了静默期,苦练内功解决模型的实际动手能力去了…
-
Anthropic 上线「做梦」功能,让 Agent 越睡越聪明
Anthropic 又又又更新了 之前 Claude Code 源码泄露的时候,大家惊奇的发现,里面有一个正在开发的功能:做梦 今天凌晨,做梦、成果评估、多 Agent 协作这三项…
-
GPT-5.5 Instant:首个被标记「高能力」的即时模型
Model 今天凌晨,OpenAI 更新了 ChatGPT 的默认模型,从 GPT-5.3 Instant 升级到 GPT-5.5 Instant。你没看错…ChatG…
-
谷歌Gemma 4深度评测:最强端侧模型并不完美,但很适合手机
近期,谷歌发布新一代开源模型Gemma 4,包括E2B、E4B、26B、31B四个规格,其中两个「小模型」E2B和E4B,可以直接在智能手机、树莓派等端侧设备部署和离线运行。 谷歌…
-
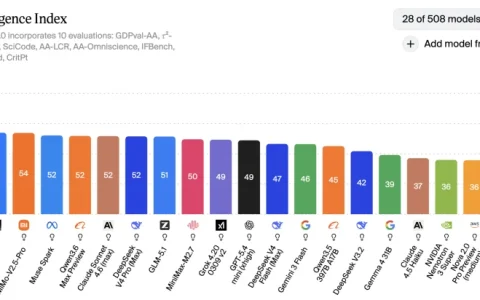
千元横测GPT、DeepSeek、Xiaomi、MiniMax的最强模型,我找到了跟Agent们的绝配
事情是酱的。 这天我在AA榜上看前28的模型感到有点陌生。 上周太集中发的后果就是光在用GPT -5.5了,小米的Mimo-V2.5-Pro,DeepSeek V4 Pro还没有放…
-
一手实测happyhorse-1.0:电影感拉满,单秒价格仅0.68元
快乐马终于来了。 立马来个威尔·史密斯吃意大利面,尝尝咸淡。 开个玩笑。 4月7日,一个没有署名的神秘模型happyhorse-1.0,突然登顶权威平台Artificial Ana…
-
在Claude Code中使用两大国产模型与世界顶级模型Claude Opus 4.7的火力比拼
图像 上个月发生了一件令我非常振奋的事情,而且持续了整整一个月。这一个月中国AI各大厂商,无论是黑马小米、Kimi和智谱以及千问、甚至期待已久的DeepSeek、还有昨天霸榜 在L…