

今天,MiniMax正式发布了其新一代旗舰大模型MiniMax M3,在多个衡量编程与Agent能力的基准测试中达到前沿水平。在真实软件工程能力基准测试SWE-Bench Pro上,MiniMax M3的表现小幅度超过GPT-5.5和Gemini 3.1 Pro,接近Claude Opus 4.7。
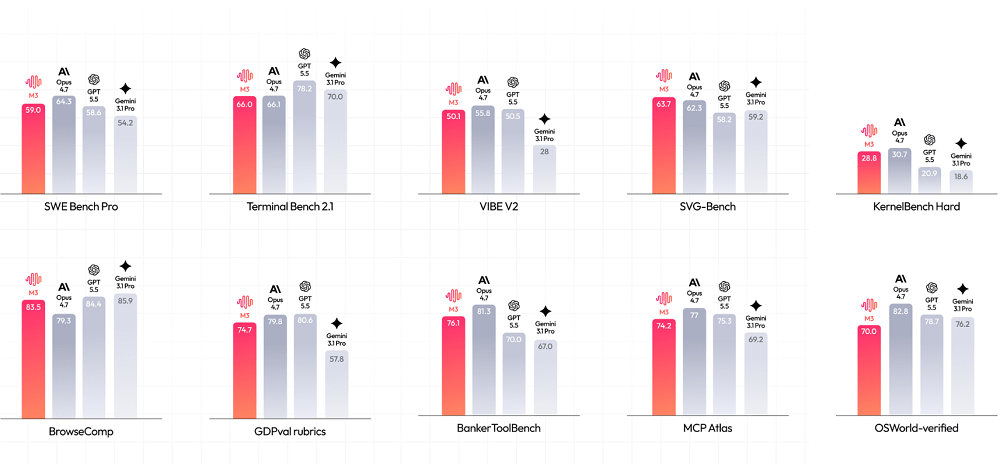
MiniMax M3采用了全新的稀疏注意力架构——MSA(MiniMax Sparse Attention)。这一架构的引入让MiniMax M3得以支持100万上下文窗口,同时也大幅提升了计算速度:与上一代采用全注意力机制的MimiMax M2相比,该模型在prefilling(预填充)阶段实现了超过9倍的加速倍率,在decoding(解码)阶段有超过15倍的加速倍率。
同时,MiniMax M3还是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。在多模态测试集OmniDocBench上,MiniMax M3的得分超过Gemini 3.1 Pro,在面向自主Agent的端到端评测框架Claw-Eval上,MiniMax M3得到最高分。
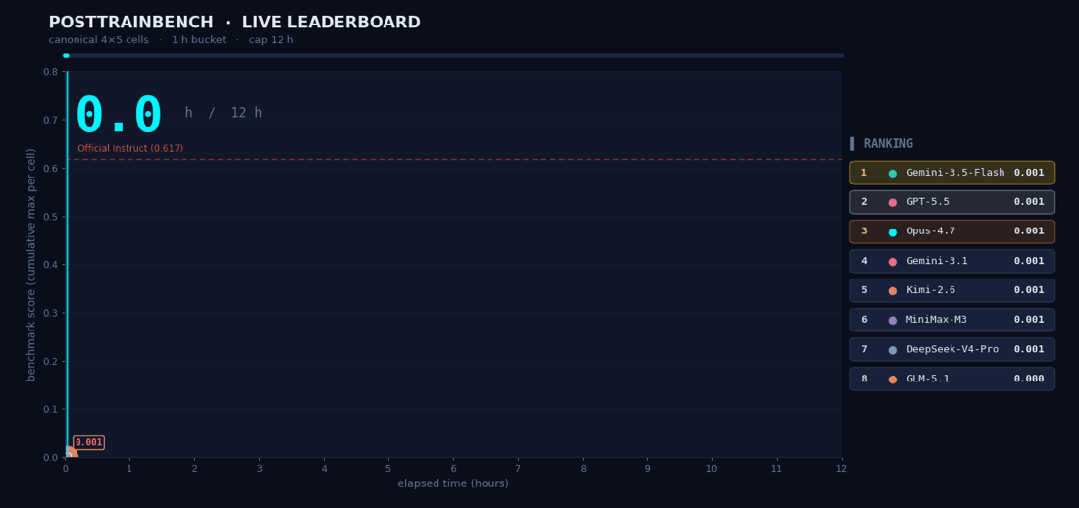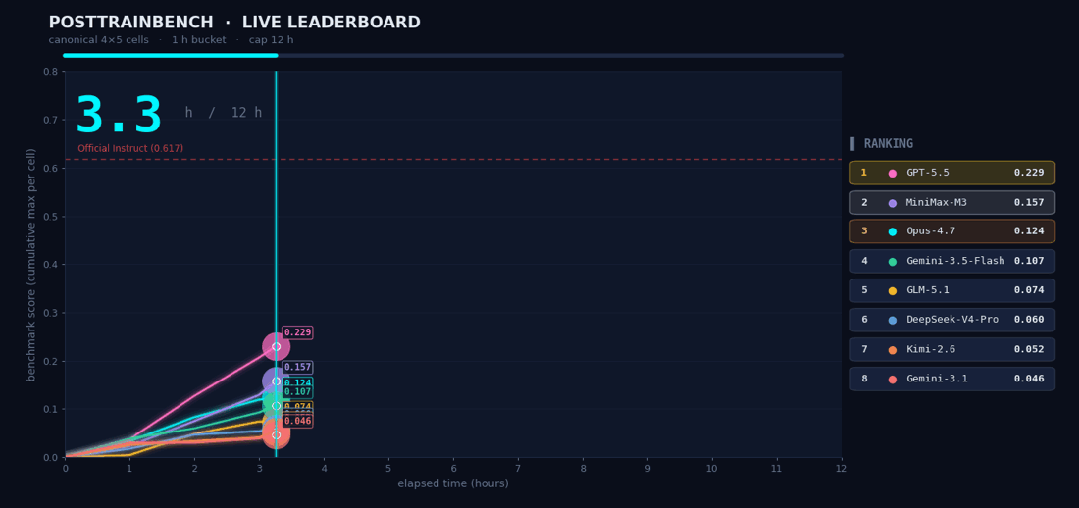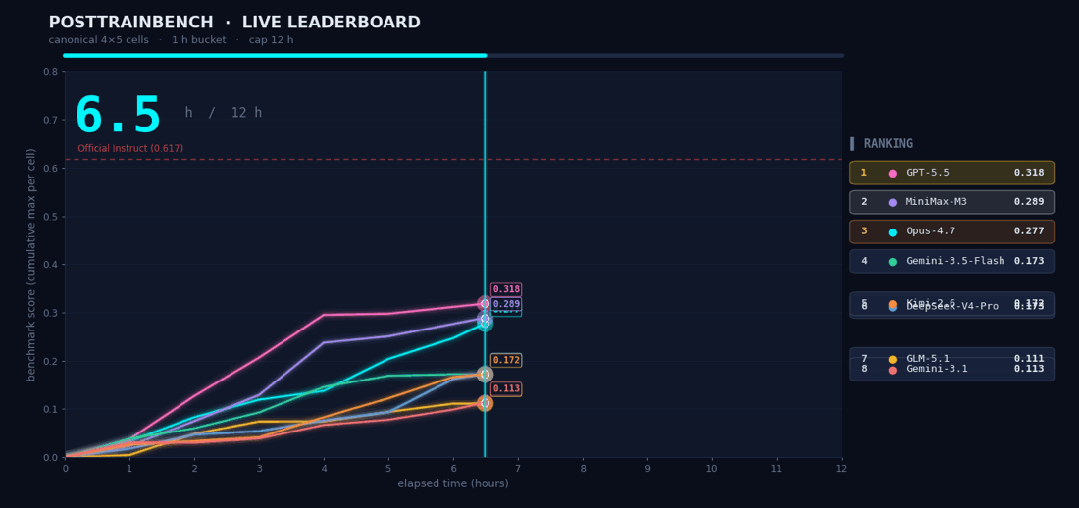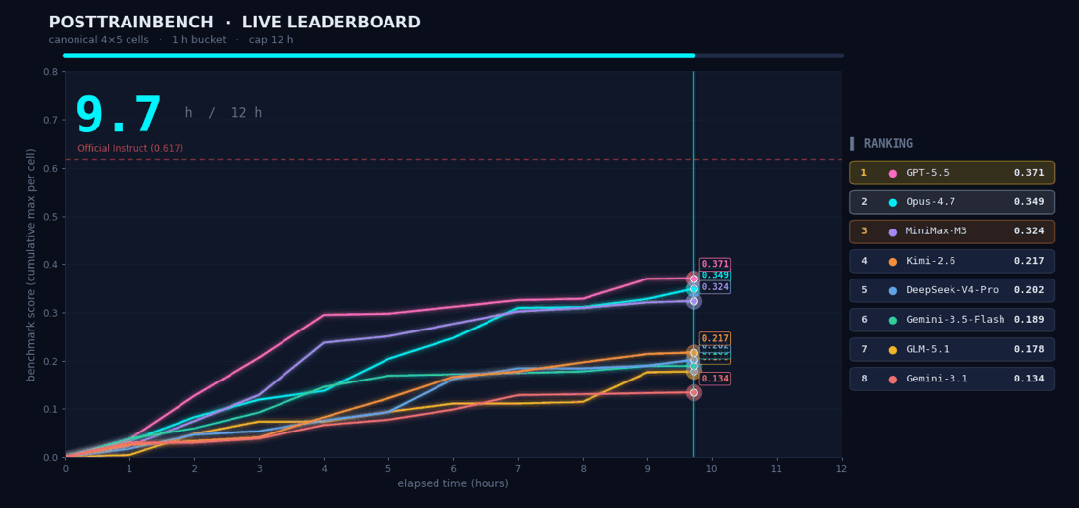
这种能力的结合,让MiniMax M3得以驾驭高度复杂的任务。在考察模型后训练能力的PostTrainBench测试中,研究团队交予M3一项挑战:在12小时内,从零开始训练4个仅有预训练基座的模型。全程无人干预,M3自主完成了“数据合成、训练、评测到迭代”的完整闭环,最终驱动这4个模型在数学推理、工具调用、代码生成等五项任务上习得了基本能力。M3最终得分0.37,紧追GPT-5.5(0.39)与Opus 4.7(0.42),并大幅领先其他模型。
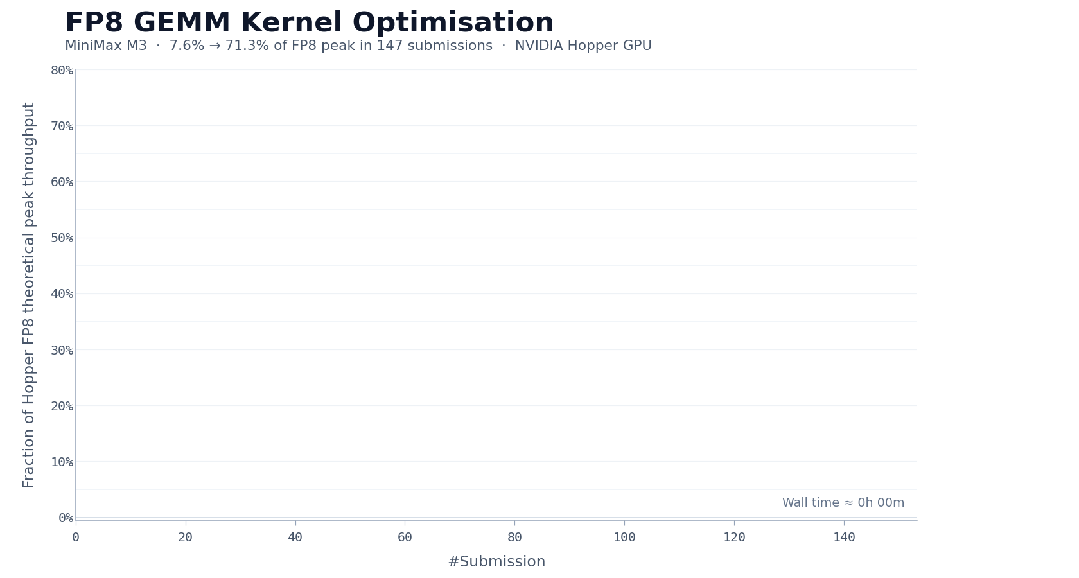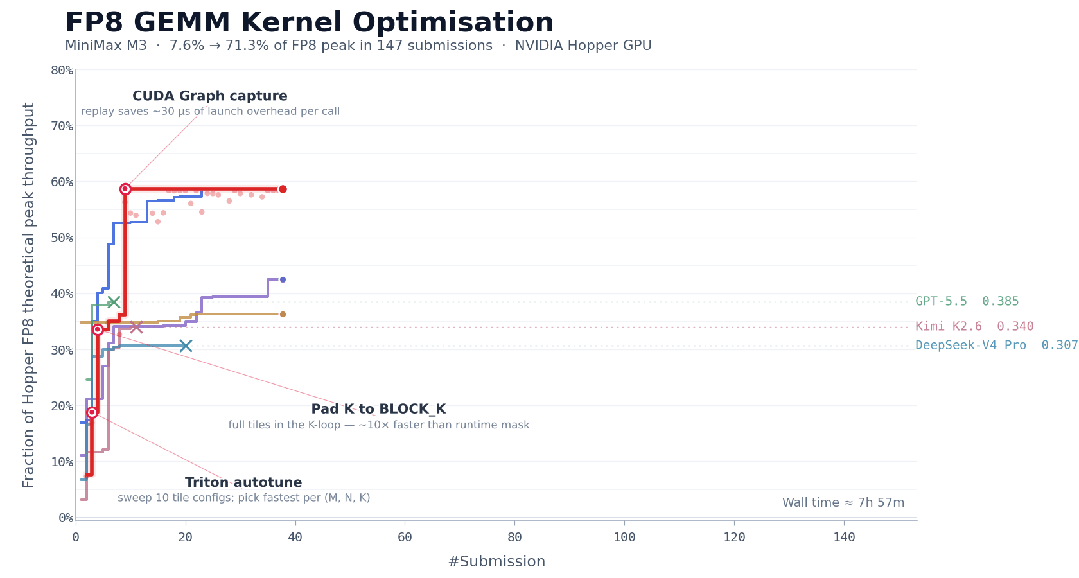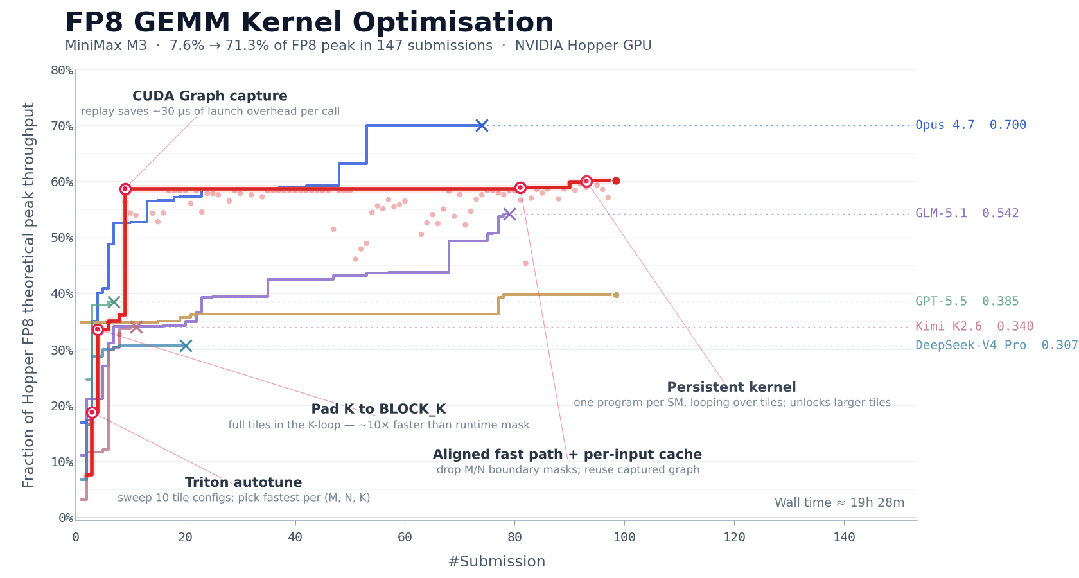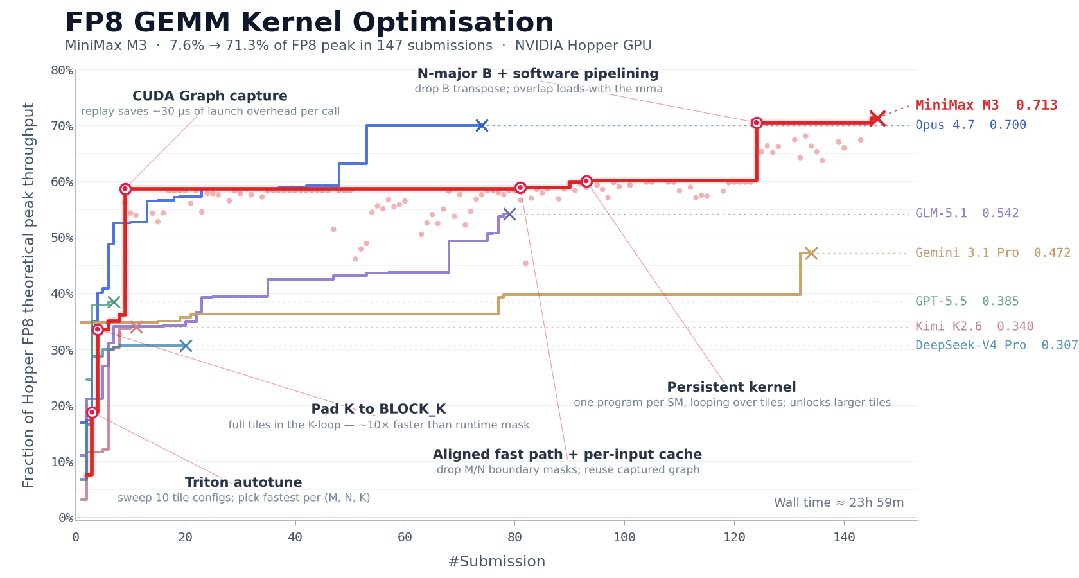
MiniMax M3还可以连续工作24小时,在147次benchmark提交、1959次工具调用之后完成对CUDA内核的优化,将Hopper FP8硬件峰值利用率从首版7.6%推进至71.3%,实现相较于原始版本的9.4×加速。
与MiniMax M3一同发布的,还有更新后的AI编程工具MiniMax Code。MiniMax Code专为M3设计、并与M3一起训练,能够充分发挥M3在长上下文、Coding/Agentic、原生多模态方面的能力。
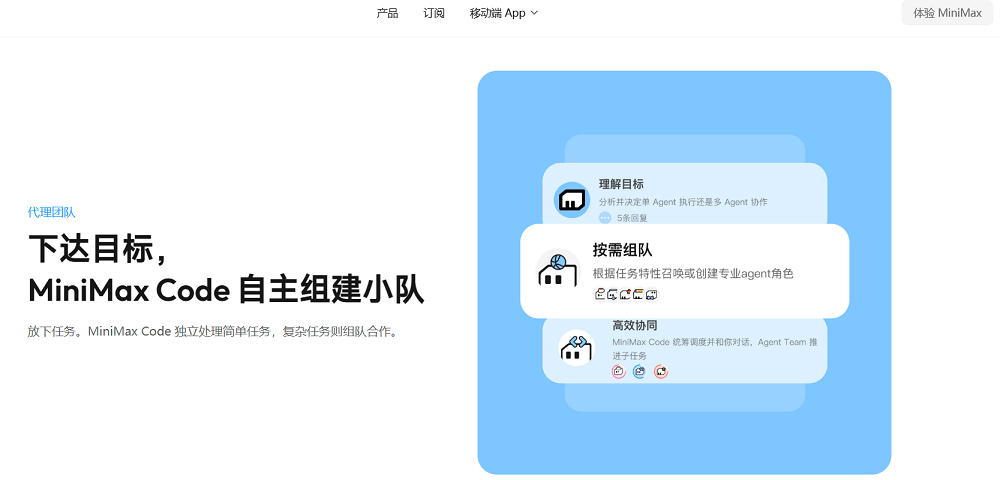
得益于M3的原生多模态能力,MiniMax Code具备Computer Use能力,可在电脑端完成跨应用、跨文件、跨系统的操作。
智东西第一时间对MiniMax M3进行了实测体验,它展现出不错的Agentic能力和扎实的多模态分析底子:能主动迭代需求、规划项目并持续反思纠错,视觉任务中对细节的描述也相当详尽。但在具体任务交付上,不少结果的完成度还不够高。
目前,MiniMax M3已在MiniMax Code、Token Plan和API中上线,接下来10天内MiniMax会更新模型的技术报告、以及开源对应的模型权重。MiniMax Code也计划在未来进行开源。
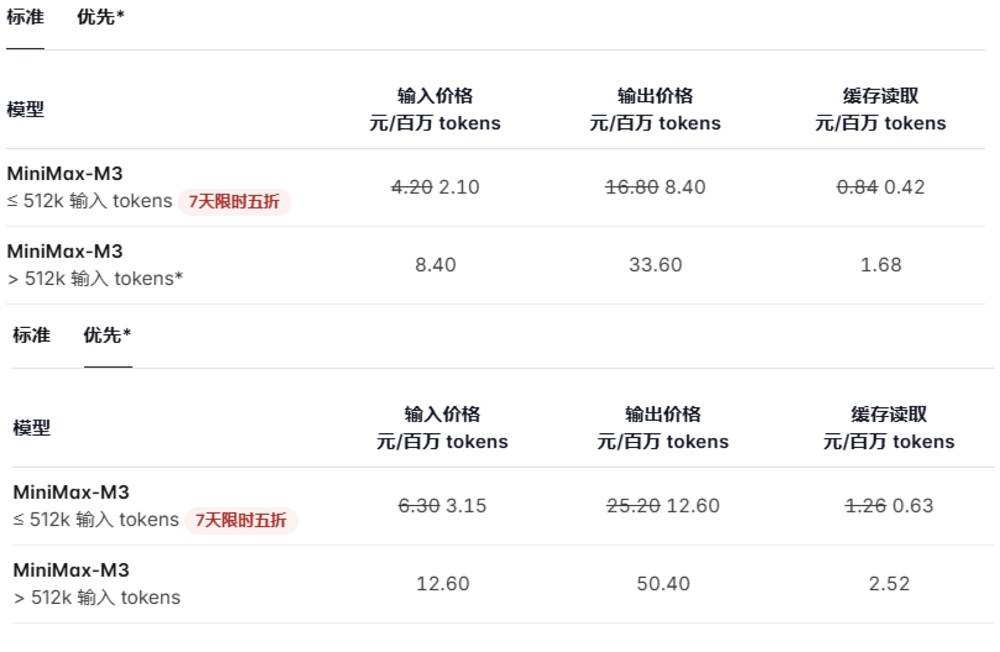
MiniMax M3的API调用价格以512k上下文为界分为两档,并提供优先调用和标准模式两种方案。512k以内上下文的调用有7天限时五折的优惠,标准模式下的调用价格分别为2.1元/百万输入tokens、8.4元/百万输出tokens,缓存读取的价格为0.42元/百万tokens。
API调用入口:
https://platform.minimaxi.com/docs/api-reference/api-overview
MiniMax Code:
agent.minimaxi.com/download
值得一提的是,MiniMax已在上周向上海证监局提交了,开启A股上市进程,冲刺A股大模型第一股。截至港股今天午间休市,MiniMax今日股价下跌14.64%至717.00港元,最新市值为2248.77亿港元(约合1942.71亿元人民币)。

一、编程与Agent能力成提升重点,能理解真实开发工作流
编程与Agent能力是MiniMax M3本次性能提升的重点,该模型也在多个相关基准测试中达到领先水平。不过,MiniMax发现,目前主流的编程测试基准存在一个比较明显的局限:很难完整反映出真实的用户体验。
现在大多数编程智能体的训练和评测,都假设任务是单轮完成的。但在实际的开发场景中,开发者往往会反复沟通需求、持续调整方案、同时推进多个任务,还要根据中间结果不断迭代优化。
为了缩小测试基准和真实体验之间的差距,MiniMax做了一个交互式用户模拟器框架。这个框架可以模拟真实开发者的协作行为,让模型在训练和评测阶段,就能接触到更接近实际工作环境的交互场景。它能还原需求补充、方案讨论、反馈修正、连续切换任务,以及复杂项目迭代这些典型行为,让智能体不只是被动执行指令,而是能够主动和用户协作完成任务。
我们迅速体验了MiniMax M3在编程与Agent任务方面的能力。
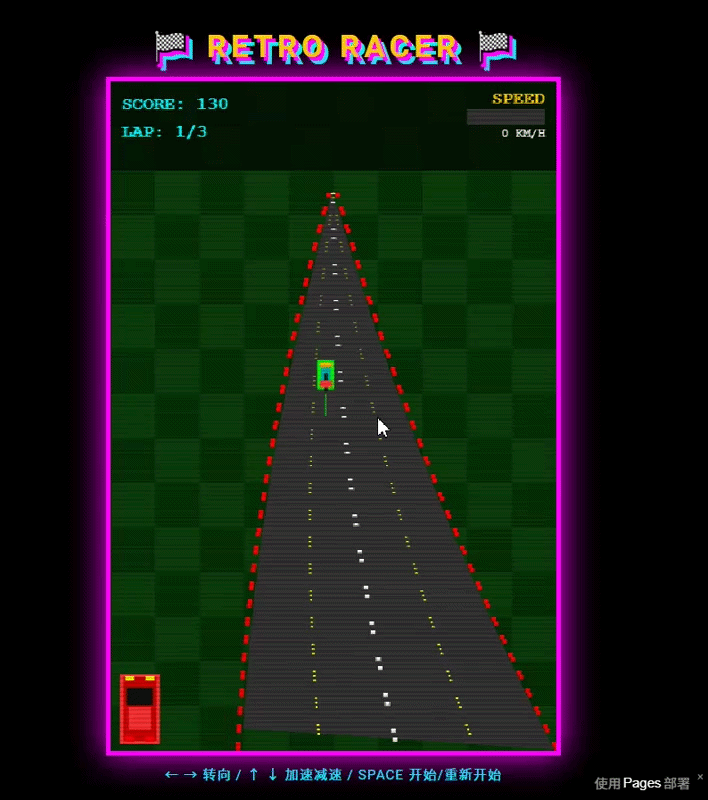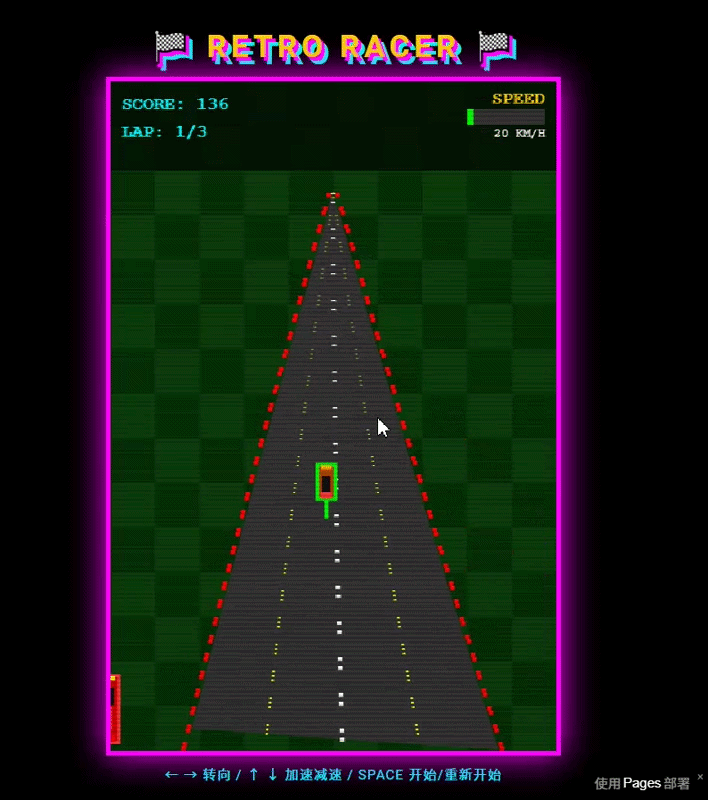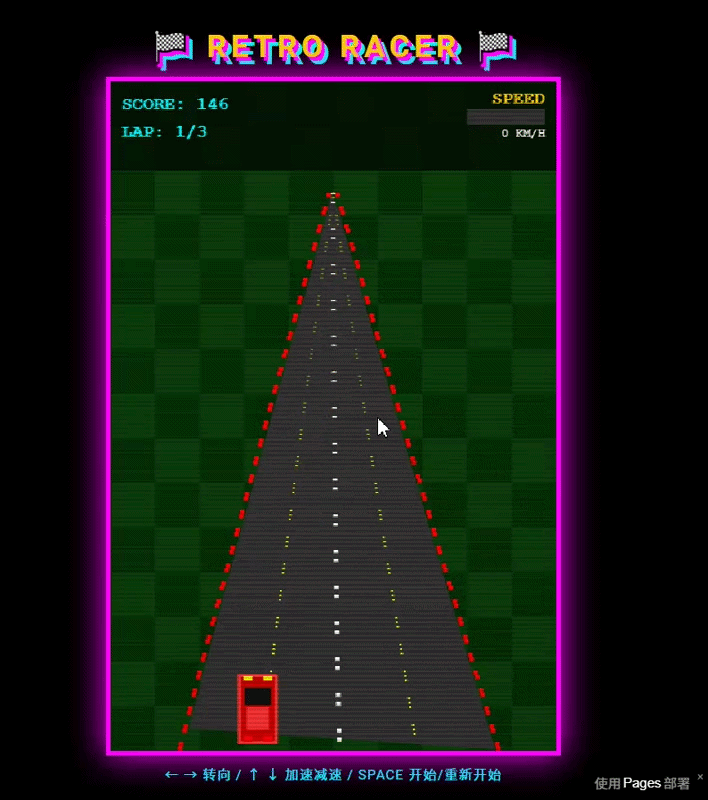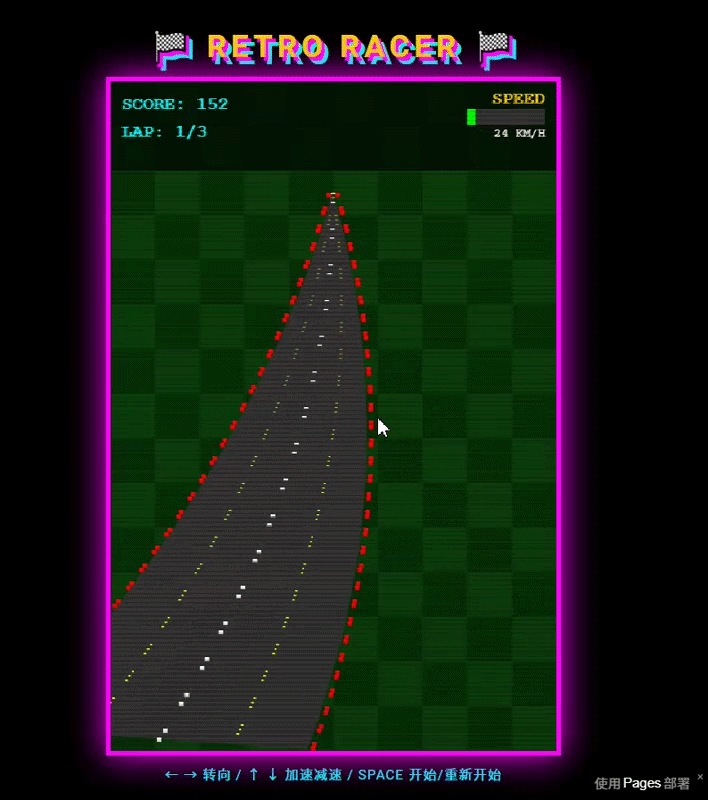
在网页游戏生成任务中,MiniMax M3制作的赛车游戏从审美上看还不错,但是实际试玩后,我们发现这一游戏的可玩性比较差。
在动态SVG图生成任务中,MiniMax M3画出了个大概,但是自行车、鹈鹕的外观很难说完全准确。

在更为复杂的任务中,我们要求MiniMax M3实现一个类似谷歌文档的文档协作系统MVP版本。MiniMax M3拿到这一任务后,先与用户讨论并确定了技术选型,然后进行了10分钟左右的思考,最终给出项目的完整规划。
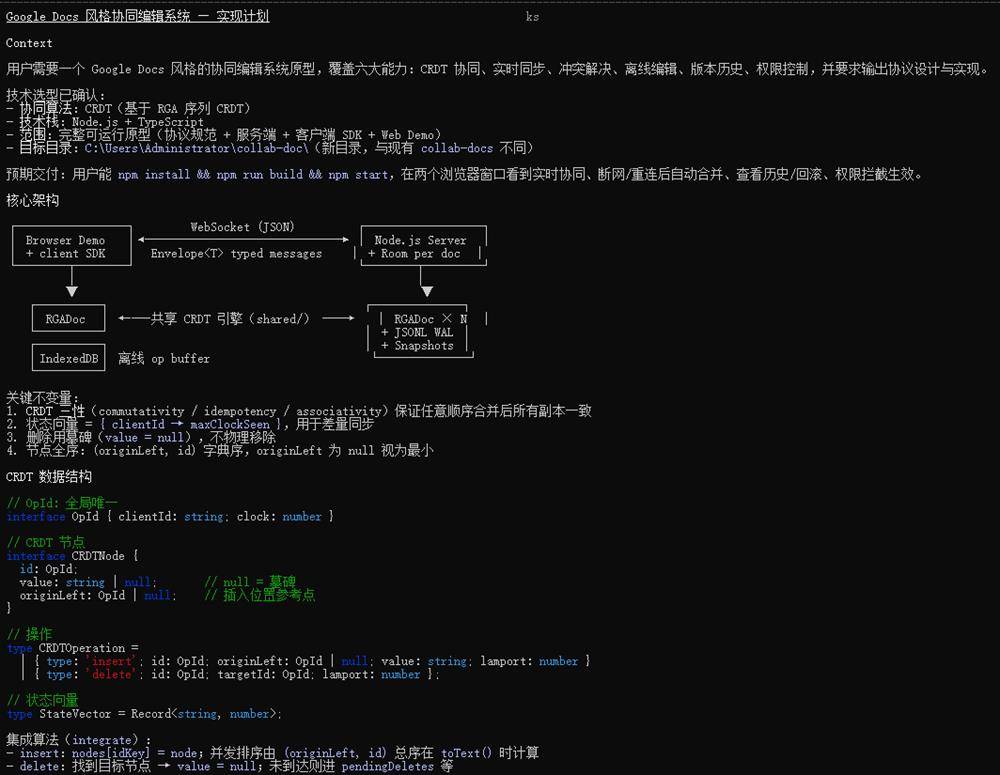
同时,MiniMax M3也考虑到了项目的验证,规划了单元测试环节,还考虑到这一项目的关键风险与权衡。
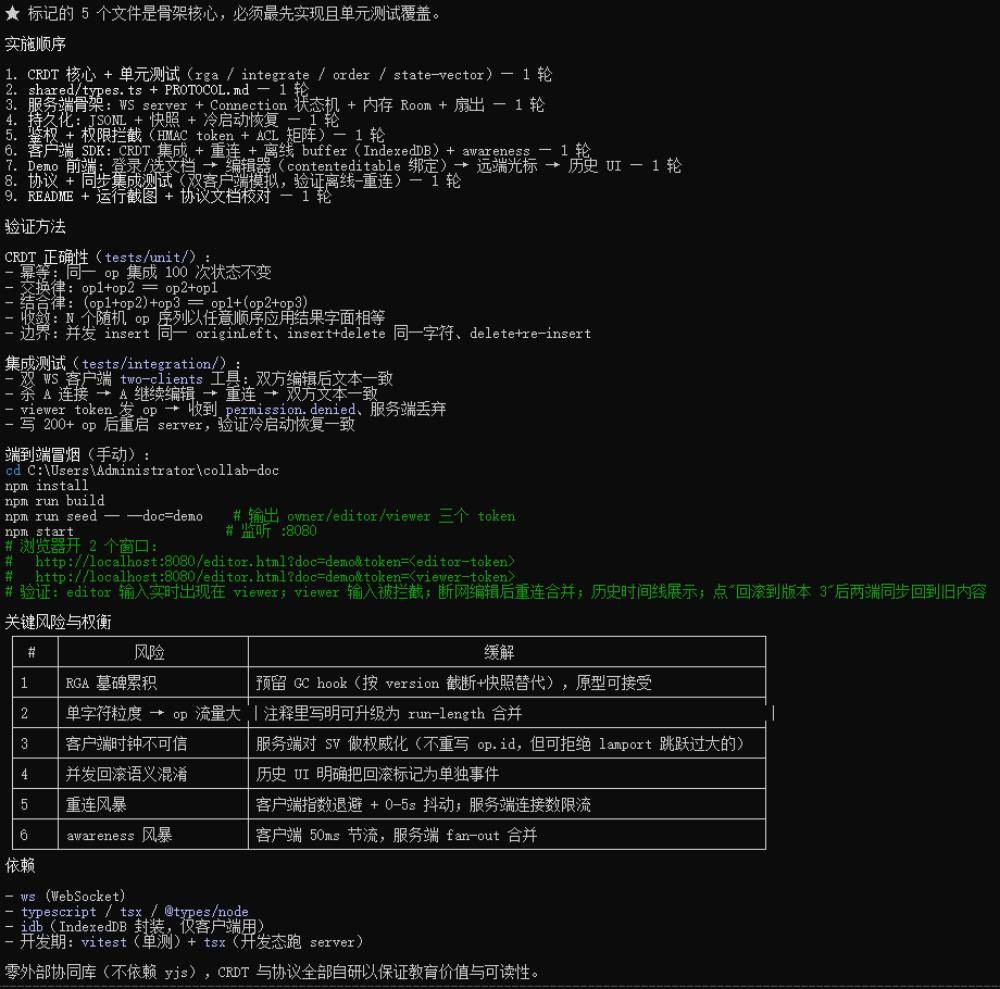
这一项目的规模较大,截至发稿,MiniMax M3还在执行CRDT单元测试编写的任务。从其执行过程中来看,MiniMax M3可以在任务中不断反思、修改自己的代码,展现出不错的自我纠错与持续优化能力。

总体来看,MiniMax M3在编程Agent任务中确实理解了真实协作流程,能主动沟通、迭代优化,但任务的完成度还有提升空间
二、具备原生多模态能力,训练数据规模达100万亿个token
多模态能力方面,MiniMax称M3是一个从Step 0开始进行多模态混合训练的模型。这种原生多模态的路线能让不同模态数据的语义空间更天然、更高度的融合。
同时,在数据配比和构成上,MiniMax的大量实验显示,Interleaved data(交错数据)对模型性能带来的提升,比一般认为的更加关键。
这些文本和图像或其他模态在序列中交替自然排列的数据,对于整体训练数据的规模扩展也很重要。在MiniMax为这些数据重构整套数据管线后,训练数据的规模提升至100万亿个token的量级。
我们迅速跑了几个多模态相关的任务。第一个任务是地点识别,我们将一张随手拍摄的照片发给MiniMax M3,并让它推断具体拍摄地点。

MiniMax M3的确对图片内容进行了详细的分析,观察到了高楼层、防尘网等细节,但它认为图中没有具体的地理标志物,无法直接锁定城市,只能判断这里应该是中国北方城市的郊区。
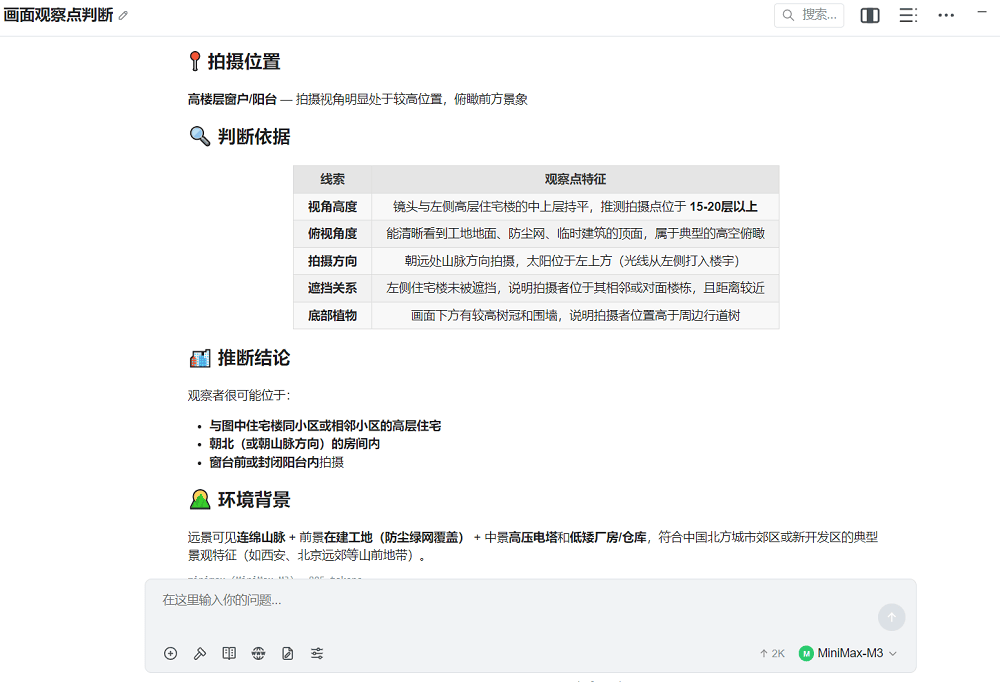
而在我们此前进行的实测中,DeepSeek识图模式、Qwen3.7 Max Preview等模型能在相同任务中将地点精确识别到离实际地点10公里左右的范围内。
我们又尝试了另一个地铁线路规划的任务。上传后,我们让MiniMax M3找出一条从昌平西山口到首都机场的最快路线。MiniMax M3推荐的路线其实并不太合理,有点“绕路”了,总耗时也比地图软件上的推荐路线要长。
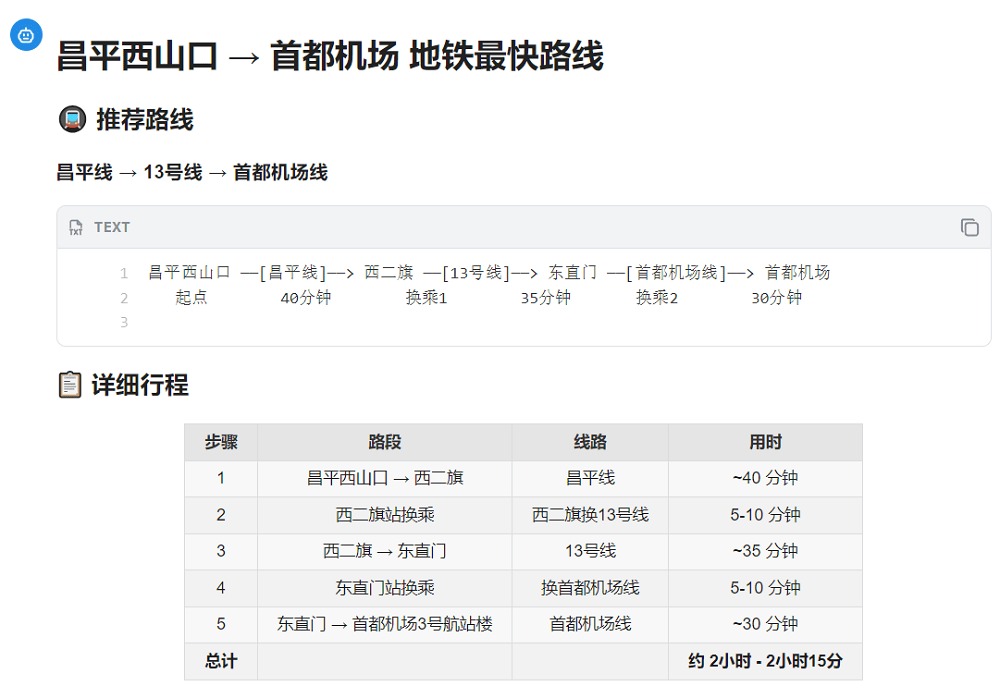
总体来看,MiniMax M3原生多模态的底子扎实,视觉描述详细,但在视觉QA任务上,跟头部模型比还有一定差距。
三、采用新型稀疏注意力方案,解码阶段加速15X
看完实测后,MiniMax M3在架构层面的创新也尤为值得关注。此前,MiniMax团队在新型注意力机制上做了不少探索,但在M2上却选择回归全注意力,当时他们给出的理由是基础设施成熟度不够、评估困难等。而到了这一代的M3,他们推出了一种名为MSA的全新稀疏注意力方案。

稀疏注意力要解决的问题,是全注意力机制计算复杂度平方级增长的“先天缺陷”。稀疏注意力通常通过引入一个初筛阶段,来避免复杂度急剧膨胀。与DSA和MoBA等现有方案相比,MSA能够更精确地对KV进行分块,从而实现更高的有效上下文覆盖。
与此同时,MiniMax团队还在算子层面做了直接优化,采用了以KV块为外层来聚合命中query的“KV outer gather Q”策略——每个块只读取一次,访存连续。
在M3当前的head配比下,这一设计的计算访存比显著优于主流方法,比开源的Flash-Sparse-Attention和FlashMoBA快4倍以上。
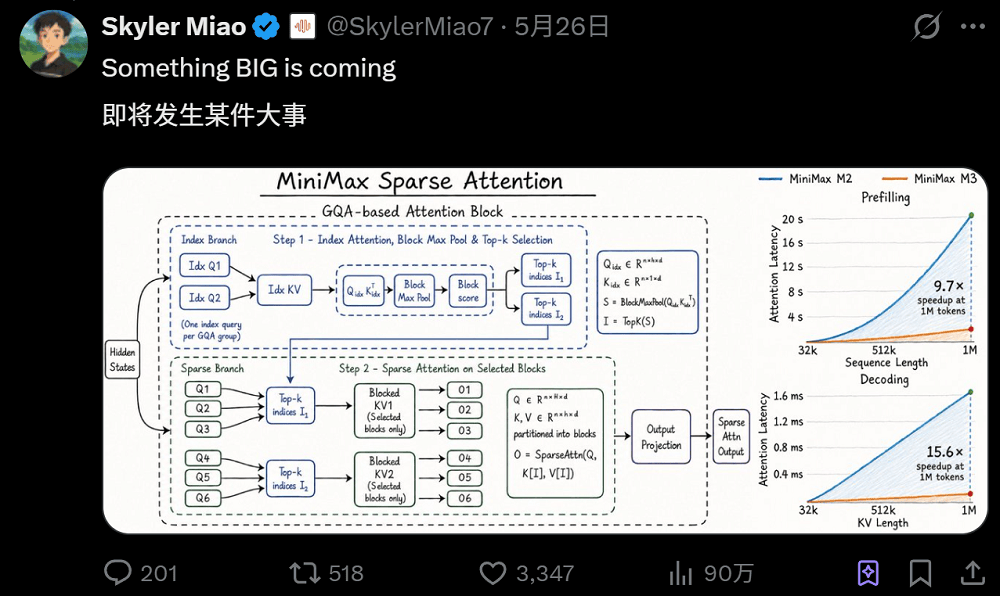
在100万上下文长度下,M3每token的计算量仅为上代模型的1/20。在prefilling阶段,加速倍率超过9倍;在decoding阶段,加速优势更达到15倍以上。而且在多个对照实验中,MSA的绝大部分能力都能与全注意力打平。
结语:国内大模型厂商积极探索架构创新
越来越多的中国大模型厂商,正通过架构维度的创新实现突围。MiniMax M3本次在稀疏注意力上的探索,以及原生多模态的尝试,让这一模型实现了效率和性能的平衡。
可以预见,围绕新型注意力机制、原生多模态混合训练与Agent端到端能力的技术探索,将成为下一阶段大模型发展的主流趋势。
本文来自转载智东西 ,观点仅代表作者本人,发现AI平台仅提供信息存储空间服务。
如若转载,请联系原作者;如有侵权,请联系编辑删除。
 微信扫一扫
微信扫一扫 








